Kafka is a great solution for handling real-time feeds. Learn how tuning Managed Kafka services can help achieve high-throughput and low latency for your streaming applications.
Apache Kafka is a widely popular distributed streaming platform that hundreds of companies such as Uber, Spotify, Coursera, and Netflix use to build horizontally scalable, efficient, and reliable real-time streaming systems. Jay Kreps, one of the creators of Kafka, perfectly describes the technology as — “Our idea was that instead of focusing on holding piles of data like our relational databases, key-value stores, search indexes, or caches, we would focus on treating data as a continually evolving and ever growing stream, and build a data system oriented around that idea.” Apache Kafka has quickly become the first choice with application developers and data management experts — according to stackshare, as many as 831 companies today reportedly use Kafka in their tech stacks.
Despite the surging popularity, Kafka can get rather complex at scale. A high-throughput messaging system with automated data retention limits can get highly unsustainable. It can lead to a cluster load and messages can get lost before they’re even seen. Add to that the systems hosting the data stream will no longer scale to meet the rising demand and ultimately become unreliable. The emergence of such platform complexities has led to the rise of managed Kafka providers. Established data management companies like Clairvoyant offer highly-reliable, fully-managed Kafka services for mission-critical applications — allowing your developers to focus on coding applications than lose sleep over system performance and throughput.
Before we dive straight into Kafka’s performance tuning capabilities and role of a managed provider, let’s get familiar with some key terminologies.
High-level Kafka Architecture
Kafka has a very simple architecture, similar to any other messaging system.
Producers (applications) send records (messages) to a Kafka broker (node) and these records are processed by target applications called consumers. Records get stored in a topic (similar to a table in a database) and consumers can subscribe to the topic and listen to those messages. Kafka topics can be very big in size, so data is further divided into multiple partitions. Partitions are the actual storage units in a Kafka messaging layer. Producer traffic is routed to the leader of each broker, using the state-administered by ZooKeeper.
The graphical representation for a high-level Kafka architecture is as shown below:
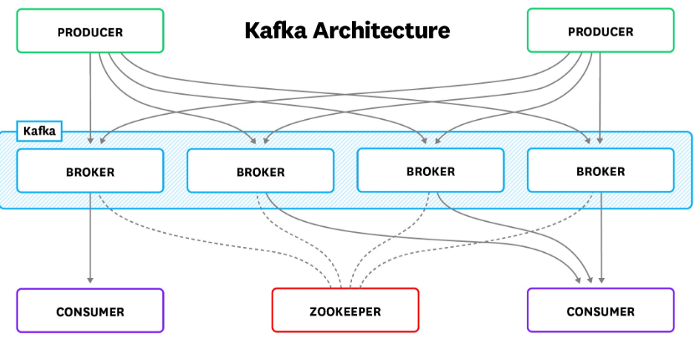
For in-depth information on Apache Kafka architecture, you can refer to the Kafka Documentation page.
Latency and Throughput:
Apache Kafka performance can be justified in two main aspects — throughput and latency.
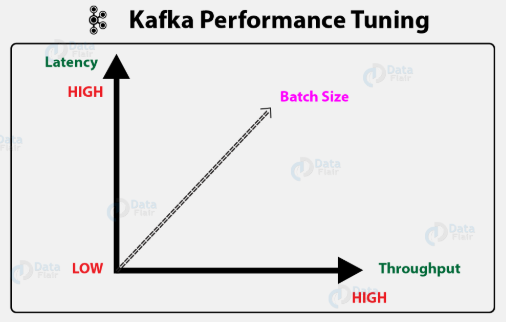
Finding the right balance between throughput, latency and the cost of the application’s infrastructure can be tricky and complicated. A well-configured Kafka cluster has just the right amount of brokers to manage topic throughput, given the required latency to efficiently process messages. To achieve the optimum balance of latency and throughput, tune your producers, brokers, and consumers for the largest possible batch sizes for your use case.
Tuning Kafka for Optimum Performance
A well-functioning Kafka cluster can handle a significant amount of data. As a requisite, It is necessary to fine-tune your Kafka deployment to maintain a solid performance and throughput from the application services that depend on it.
Following are the best performance tuning practices, listed in 3 different categories
- Kafka producer performance tuning
- Batch size: Modifying batch size in your producer configuration can lead to significant gains in throughput. As a general rule of thumb, you should increase the batch size if you have available memory. Too large a batch can keep the consumer groups idling. A small batch, for instance, might produce low throughput and high overheads. That being said, a small batch is much better than not using batches at all.
- Acknowledgments (ack-value): The ack-value is a producer configuration parameter in Apache Kafka to acknowledge signals passed between communicating processes. In Kafka 0.10.x, the setting is ‘acks’; For maximum throughput, set the value to 0. For high durability and high throughput, set the ack-value to 1. For no data loss, set the value to -1. Configuring acks-value on your producers is mandatory, as messages can get silently lost if done otherwise.
- Compression: The producer or sender can compress messages, whereas the consumer can decompress them. It is recommended to compress large messages or files to shrink the disk footprint. Kafka isn’t built to stream large files. Instead, place your large messages on any other storage platform such as Amazon S3 instead of directly transmitting them through Kafka.
It is important to maintain a good balance between building up batches and the producer publish rate. Defining an optimum batch size is mostly case dependent. A managed Kafka provider continuously tracks producer traffic to maintain an ideal batch size. Say you have a real-time application — the batch sizes need to be much smaller to avoid up-heads. A performance load test can be a good medium to infer the number of messages a producer can produce in a specific period of time. Please refer to the Kafka Benchmarking blog for practical tuning configurations to load-test your Kafka cluster workloads.
2. Kafka broker performance tuning
- Number of topics and partitions: If partition leaders are not balanced properly, one might get unevenly overloaded affecting system efficiency. A topic can be divided into partitions over several machines allowing multiple consumers to read a topic in parallel. This very architecture allows high message throughput — greater the parallelization, higher the throughput. Having said that, you typically don’t want to use more partitions than needed since increasing the partition count also increases the volume of open server files and replication latency.
- Number of replicas: Depending on the criticality of your system, you want to ensure that there are enough replication sets to hold your data. Higher replication can result in additional requests between the partition leader and followers — resulting in more disk and CPU usage, thereby increasing latency and decreasing throughput.
It is critical to set the right number of partitions per broker to allow maximum availability and avoid data loss. Broker capacity planning can be tricky as it mainly depends on the type of data coming in — say you wish to store large records rather than consistently push smaller real-time records. For a detailed understanding of the same, a managed Kafka provider uses custom monitoring tools to track the overall cluster status and partition throughput. The number of partition leaders per instance or the status of replicas helps diagnose if there is a steady flow of data or not.
3. Kafka consumer performance tuning
- Consumer connections: Partitions get redistributed between consumers each time a consumer connects or drops out of the consumer group. Even if a single consumer loses connectivity, the whole group gets impacted and will not be available during a reconnect. Hence, it is strongly recommended to secure all consumer connections to ensure system stability.
- Number of consumers: Ideally, the number of partitions = the number of consumers. If consumers>producers, some consumers will be left idling, and you will basically be wasting client resources. And on the other hand, if partitions>consumers, only a few consumers will read from multiple partitions. The greater the number of consumers you have, the larger is the risk that one may disconnect and affect all other consumers in that group.
Simply provisioning more consumers at the other end of the pipeline is not the answer to reduce latency and achieve maximum throughput. A cost-effective approach to set the right consumer offset is key. Good performance and product stability are usually seen by writing efficient code and using better libraries. A managed Kafka provider can deliver the engineering expertise to ensure that consumers only read those records that have been commissioned.
Also, for in-depth performance analysis of the above-mentioned parameters, read how Clairvoyant managed services utilized Kafka streaming platform to perform large-scale processing of electronic documents on-demand for a leading health insurance company in America.
Fully-Managed Kafka Services
We observed how several considerations come into play when fine-tuning your Kafka cluster. It can certainly be an arduous, resource-demanding task to set the right metrics in order to achieve maximum throughput and efficiency from your cluster.
A managed Kafka service provider can deliver the experience of using Apache Kafka without requiring complete knowledge on how to operate it to maximize efficiency -
- Explore all key metrics to keep tabs on the performance of your Kafka cluster. Meticulously monitor your overall cluster performance using custom alerts to provide accurate results.
- Deliver 30-minute SLA responses with 99% uptime guarantees to allow fault-resilient system performance.
- Provide complementary eco-system support for services like Kafka Schema Registry, Kafka Manager, Kafka REST, Kafka Connect — to better drive throughput rate.
- Well-informed on all the latest technology trends, any new features or bug fixes — with active project participation on a day-to-day basis.
Streaming platforms like Apache Kafka are changing the way people engage with services. As mentioned in the article, these host of capabilities come at a cost — complexity. Fine-tuning your Kafka cluster can greatly improve performance, throughput, and recovery time in the event of failures. Managed Kafka services can make the experience of using Kafka as fast and effortless as possible. An established dataops Kafka provider like Clairvoyant has the knowledge and expertise to fully hone your Kafka cluster environment in the most efficient, cost-effective manner.