The Cloud War is heating up. Google and AWS have two directly competing serverless querying tools: Amazon Athena and Big Query.
In this blog, we will take a closer look at these two services and compare their real-world performance executing a series of SQL queries against the same dataset.
Amazon Athena
Amazon Athena is a serverless way to query your data that lives on S3 using SQL. It excels with datasets that are anywhere up to multiple petabytes in size. Queries cost $5 per terabyte of data scanned with a 10 MB minimum per query.
Data can be stored in CSV, JSON, ORC, Parquet, and even Apache Weblogs format. You can even use compressed CSV files in GZIP format to save on query costs and improve performance over regular, uncompressed CSV files.
It’s important to note that Athena is not a general-purpose database. Under the hood is Presto, a query execution engine that runs on top of the Hadoop stack.
Google BigQuery
Google BigQuery can be used via its Web UI or SDK.
BigQuery allows you to query tables that are native (in Google Cloud), external, or in logical views. Users can load data into BigQuery storage using batch loads or via stream and define the jobs to load, export, query, or copy data. The data formats that can be loaded into BigQuery are CSV, JSON, AVRO, and cloud datastore backups.
Let’s look below some of the cost aspects of BigQuery:
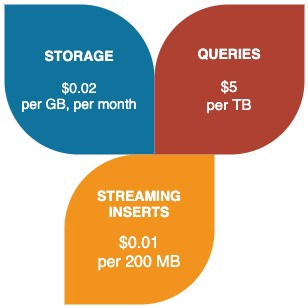
Athena vs. BigQuery — A Pricing Comparison
Both Athena and BigQuery bill at $5/TB queried. However, not all terabytes are created equal. Athena charges for bytes read from S3; compressing data to reduce its size thus saves costs for both queries and storage. The Athena pricing documentation (https://aws.amazon.com/athena/pricing/) mentions this strategy specifically: “Compressing your data allows Athena to scan fewer data.”
Behind the scenes, BigQuery also compresses data, but this is invisible to the user. Here’s the big difference with Athena — storage and queries are billed by decompressed bytes (https://cloud.google.com/bigquery/pricing#data), and the difference in calculated data size can be dramatic.
Benchmarking Athena vs BigQuery
In order to perform benchmarking between Athena and BigQuery, we will be using a very popular open-source New York taxi trips dataset.
We will be running various queries that would include various types of aggregations and include analytical functions that would help us determine the performance of both services.
In order to get the data, we can use the below link to fetch data for all the Yellow taxi trip records:
Here, you can find data for various years of the New York Taxi trips, which can benchmark Athena and BigQuery by cost and performance.
In order to download the data for multiple years together, we used the following python script:
The above script will download the data by a specific year. You need only specify the year you want to download.
Once the data is downloaded, we converted the data to Parquet format using Apache Spark so that we have a fixed data format.
In order to perform the benchmarking, we would be using approximately 145 GB dataset for New York Taxi data.
Below are the queries which we ran in order to benchmark Athena and BigQuery:
Results
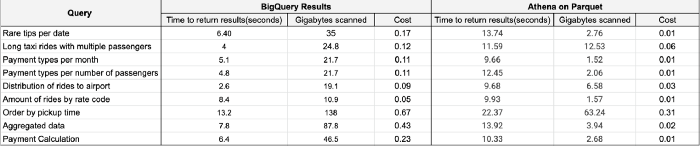
From the above results, we can clearly see that the time taken for BigQuery to process data is less than Athena.
BigQuery is a sure-shot winner when compared with Athena but looking from the cost perspective (in $) Athena is quite cheap and is budget-friendly.
Summarizing the difference between the two
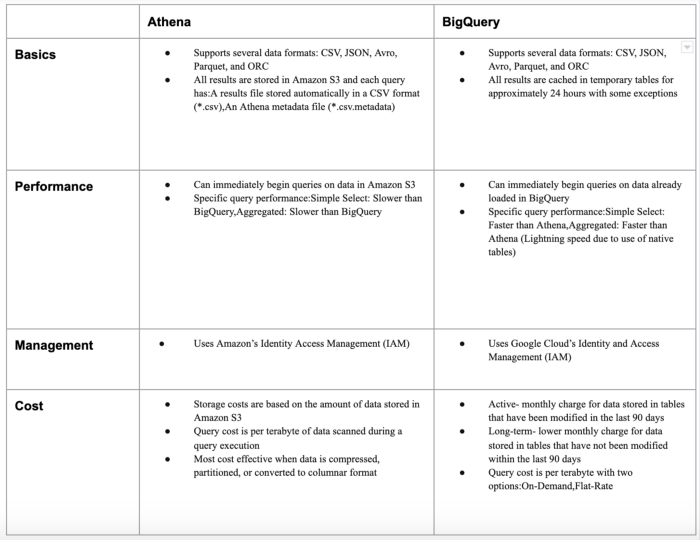
Conclusion
After the above comparison, it’s clear that BigQuery outperforms Athena when we look into time to return results; the choice ultimately depends on the needs of your business and the cost.
BigQuery allows you to run SQL-like queries on multiple terabytes of data in a matter of seconds, and Athena allows you to quickly run queries on data from Amazon S3.
Amazon Athena is simple yet has efficient quality. No initial setup is required, which makes ad hoc querying easy. It’s practical for simple and aggregated queries and is relatively cost-effective as compared to BigQuery.
Hence if you are looking to run your analysis on Petabytes of data, then BigQuery is surely an excellent data engineering process for that.