In this blog, we are going to explore how to Load Test Apache Kafka, a distributed messaging system platform, by using Kafka performance Tools/Scripts.
Kafka Introduction
Apache Kafka is a streaming message platform. It is designed to be high-performance, highly available, and redundant. Examples of applications that can use such a platform include¹:
• Internet of Things - TVs, refrigerators, washing machines, dryers, thermostats, and personal health monitors can all send telemetry data back to a server through the Internet
• Sensor Networks - Areas (farms, amusement parks, forests) and complex devices (engines) can be designed with an array of sensors to track data or current status
• Positional Data - Delivery trucks or massively multiplayer online games can send location data to a central platform
• Other Real-Time Data - Satellites and medical sensors can send information to a central area for processing
The general setup is quite straight-forward. Producers send records to the Kafka cluster which holds these records and transfers them out to consumers:
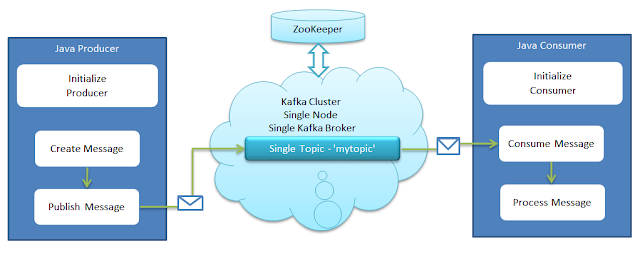
The key abstraction in Kafka is the topic. Producers publish records/messages to a topic, and consumers subscribe to one or more Kafka topics. A topic is a queue of messages written by one or more producers and read by one or more consumers. The producers produce messages, either they create them or they are connected to an API creating messages. The messages are published to the broker, and the consumers read the messages from the broker
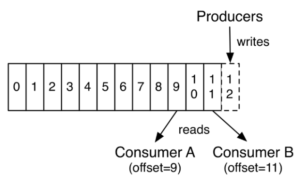
The following figure shows a conceptual image of how Kafka producers write to a topic and how the consumers read from the same topic-
For further information on Apache Kafka, please refer to Kafka Documentation.
Kafka Benchmarking
The following sections introduce the concepts that will help you balance your Kafka workloads and then provide practical tuning configuration to address specific circumstances.
The most accurate way to model your use case is to simulate the load you expect on your own hardware. You can do this using the load generation tools that ship with Kafka, kafka-producer-perf-test, and kafka-consumer-perf-test.
The kafka-*-perf-test tools can be used in several ways. In general, it is expected that these tools be used on a test or development cluster.
• Measuring read and/or write throughput
• Stress testing the cluster based on specific parameters (such as message size)
• Load testing for the purpose of evaluating specific metrics or determining the impact of cluster configuration changes
We need to perform a load test for both, i.e Producer and Consumer, to conclude how many messages a producer can produce and a consumer can consume in a given period of time.
The key statistics we are looking for are mentioned below:
- Throughput (messages/second) on the size of data
- Throughput (messages/second) on the number of messages
- Total messages
- Total data
1. Testing the Producer
Let’s test our producer by sending 1000000 records to the test topic. Run the following command in your terminal.
kafka-producer-perf-test --topic test --num-records 1000000 \
--throughput -1 --producer-props bootstrap.servers=[serverIP]:
9092 \ batch.size=1000 acks=1 linger.ms=100000 buffer.memor
y=4294967296 \ compression.type=text request.timeout.ms=
300000 --record-size 1000
The flags of most interest for this command are:
--topic:The topic the Performance test will write to
--num-records:The total number of records to send for the test
--throughput:The maximum throughput for the test
--producer-props:The producer properties
bootstrap.servers:The location of one of the Kafka brokers
batch.size:The batch size in bytes
compression.type=text
--record-size:The size of each record in bytes
Once the test is completed some stats will be printed on terminal, something like;
1000000 records sent, 9999.400036 (14.30 MB/sec), 0.38 ms avg
2. Testing the Consumer
Run the below command in your terminal.
kafka-consumer-perf-test --topic test --zookeeper <serverIP:2181> \
--messages 10000000 --threads 2
The flags of most interest for this command are:
--topic : The topic to consume from.
--zookeeper:The connection string for the zookeeper
connection in the form host:port. Multiple
URLS can be given to allow fail-over.
--messages: The number of messages to consume .
--threads: Number of processing threads.
Once the test is completed, you can see the stats in the terminal.
start.time,end.time,data.consumed.in.MB,MB.
sec,data.consumed.in.nMsg,nMsg.sec
2019–03–15 06:53:31,1602019–03–15 06:54:06,
14305.1147,399.9417,10000000,279579.5124
- start.time, end.time: shows test start and end time
- data.consumed.in.MB: shows the size of all messages consumed
- MB.sec: shows how much data is transferred in megabytes per second (Throughput on size)
- data.consumed.in.nMsg: shows the count of the total messages consumed during this test
- nMsg.sec: shows how many messages were consumed in a second (Throughput on the count of messages)
By using the Producer and Consumer performance results, we can benchmark and decide the batch size, message size, and the number of maximum messages that can be produced/consumed for a given Kafka configuration.
All the above tests used the default configurations of Kafka, there can be multiple scenarios and use cases where we can test and take the performance stats for Kafka Producer and Consumer, some of those cases can be :
- Change the number of topics
- Change the async batch size
- Change message size
- Change the number of partitions
- Change the number of Brokers
- Change the number of Producer/Consumer etc
- Change the compression Type
Conclusion
To sum it all up, we have seen how to use Kafka shipped performance tools for load testing the Apache Kafka.
Performance tuning involves two important metrics:
• Latency measures how long it takes to process one event
• Throughput measures how many events arrive within a specific amount of time
Most systems are optimized for either latency or throughput. Kafka is balanced for both. A well-tuned Kafka system has just enough brokers to handle topic throughput, given the latency required to process information as it is received. Our data engineering tools can aid you in implementing Kafka efficiently.
Tuning your producers, brokers, and consumers to send, process, and receive the largest possible batches within a manageable amount of time results in the best balance of latency and throughput for your Kafka cluster.²
~We hope the technique presented here can be useful for readers to benchmark their Kafka Clusters.
References
1. https://docs.cloudera.com/documentation/kafka/1-4-x/topics/kafka_performance.html