Compelling advantages of building data lake on the cloud with a scalable architecture
Our data footprint is constantly increasing. The world is filled with data but as the above image suggests, only 3% of it has been put to appropriate use. The need of the hour is not more data, but the capability to use it efficiently. Clairvoyant is an organization that is committed to helping companies uncover the true potential of their data. In the past 8+ years, Clairvoyant has helped 75+ organizations build a rational and data-driven decision-making process.
Now, through this blog, we wish to explain how data can be used efficiently. One of the first steps in this process is the ingestion of data into the data lake to gather it all in one place. As a precursor to this step, it is necessary to architect a data lake. Here, we also explain the process of architecting a data lake and building a process for data ingestion in it.
Data lakes are often used to consolidate all of an organization’s data in a single, central location, where it can be saved “as is,” without the need to impose a schema or structure on it upfront. Data in all stages of the refinement process can be stored in a data lake; raw data can be ingested and stored right alongside an organization’s structured, tabular data sources (like database tables), as well as intermediate data tables generated in the process of refining raw data. Unlike most databases, data lakes can process all data types including images, video, audio, and text.
Challenges with Legacy Data Architectures
- It’s difficult to move the data across silos
- Handling dynamic data and real-time processing becomes challenging in legacy data architectures
- It’s difficult to deal with format diversity and the rate of change of data
- Complex ETL processes
- Difficult to find people with adequate skills to configure and manage these systems
- It’s difficult to integrate with the explosion of available social and behavior tracking data
We saw above, the major challenges we face while building a data lake. Now let’s try to understand data lake and its benefits over traditional data warehouses in depth.
What is a Data Lake?
- Data: Non-relational and relational data from IoT devices (a single sensor data would be Non-relational, whereas multiple sensor data combined with each other to draw inference becomes relational), web sites, mobile apps, social media, and corporate applications.
- Schema: Defined at the time of analysis
- Performance: Optimized using low-cost storage and open data formats
- Data Quality: Any data that may or may not be curated (ie. raw data)
- Users: Data scientists, Data engineers, and Business analysts (using curated data)
- Analytics: Machine learning, predictive analytics, data discovery, and data profiling (Data quality checks and Data insights)
Benefits of a Data Lake:
- Data storage in native format — A data lake eliminates the need for data modeling at the time of ingestion. We can do it at the time of finding and exploring data for analytics. It offers unmatched flexibility to glean insights from a business or domain.
- Scalability — It offers scalability and is relatively inexpensive compared to a traditional data warehouse when we take scalability into account.
- Versatility — A data lake can store multi-structured data from diverse sources. In simple words, a data lake can store logs, XML, multimedia, sensor data, binary, social data, chat, and people data.
- Schema Flexibility — Traditionally, schema necessitates the data to be in a specific format. This is great for OLTP (Online Transactional Processing) as it validates data before entry. But for analytics, it’s an obstruction as we want to analyze the data as-is. Traditional data warehouse products are schema-based but hadoop data lake either allows you to be schema-free or lets you define multiple schemas for the same data. In short, it enables you to decouple schema from data which is excellent for analytics.
- Supports not only SQL but more languages — The traditional data-warehouse technology mostly supports SQL, which is suitable for simple analytics. But for advanced use cases, we need more ways to analyze the data. A data lake provides various options and language support for analysis. It has Hive/Impala which supports SQL but also has features for more advanced needs. For example, to analyze the data in a flow you can use PIG, and to do machine learning you can use Spark MLLib.
- Advanced Analytics — Unlike a data warehouse, a data lake excels at utilizing the availability of large quantities of coherent data along with deep learning algorithms. It helps in real-time decision analytics.
We will now move onto building a data lake on the AWS cloud and the major benefits attached to it.
ESG research shows roughly35–45% of organizations are actively considering cloud computing solutions for functions like Hadoop, spark, databases, data warehouses, and analytics applications. It makes sense to build your data lake in the cloud for a number of reasons and some of the key benefits include:
1) Runs on top of secured AWS data centre Infrastructure
2) Lets you build a secure Data lake in days
3) Offers compliance with PCI DSS, HIPAA, and FedRAMP
4) Lets you encrypt data at rest and in-transit
Logical Architecture for a Data Lake
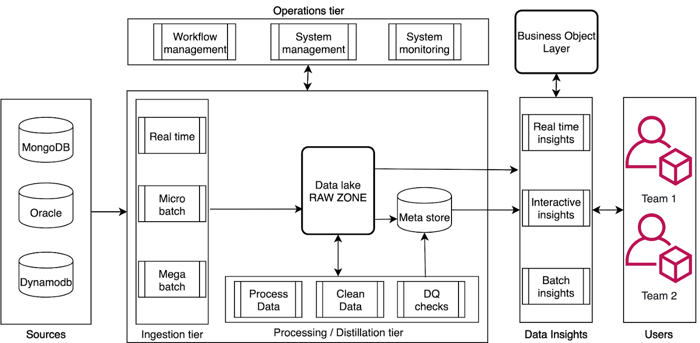
Services used for building a Data Lake on AWS
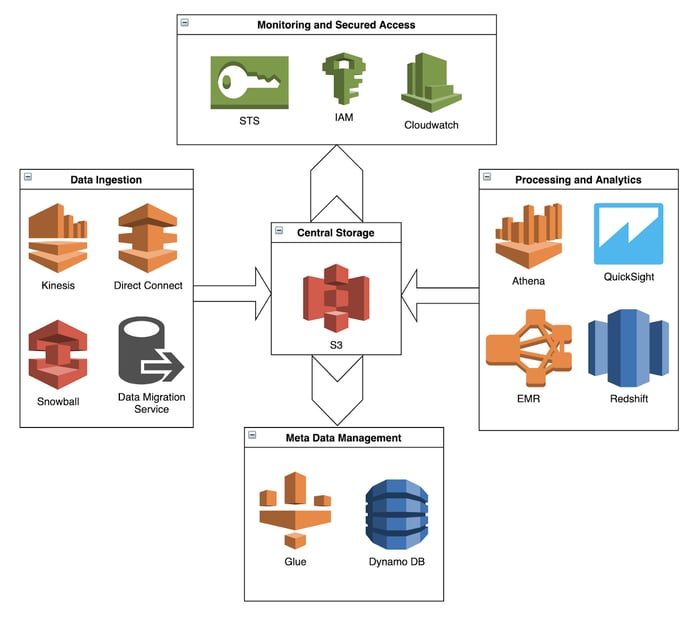
S3 as a Data Lake Storage Platform
- Virtually unlimited scalability
- 99.999999999% durability
- Integrates with a broad portfolio of AWS and third-party
- Decoupling of storage from computation resources and data processing resources
- Centralized data architecture
- Integration with cluster-less and serverless AWS services
- Standardized APIs
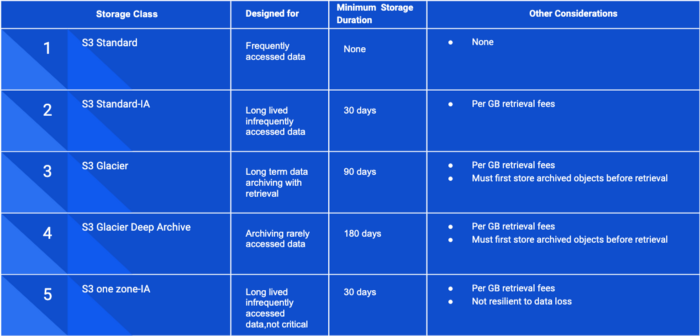
Different S3 Storage Classes for storing Hot and Cold data
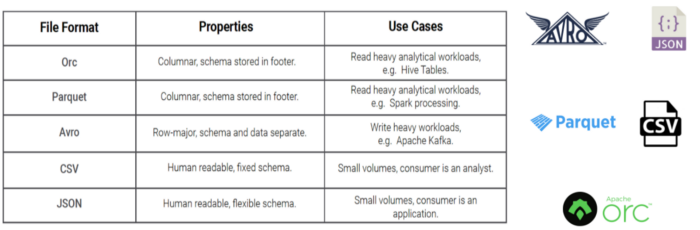
Open data formats on S3
Ingestion Tier
The ingestion tier mainly consists of the below categories-:
- Real time
- Micro batching
- Mega batching
Let’s compare some of the tools and technologies used for importing data to Data lake:
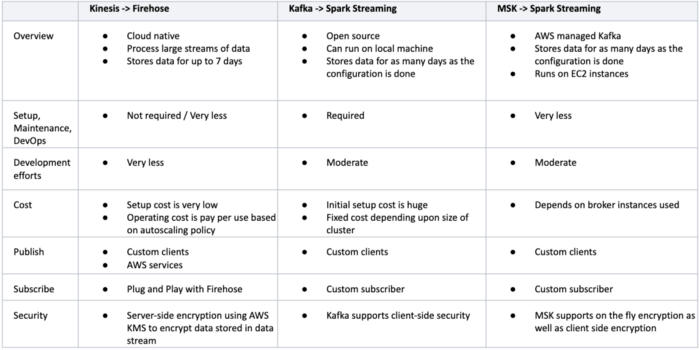
Comparison of tools used for Real-time data streaming
Comparison of tools used for Micro and Mega Batch data ingestion
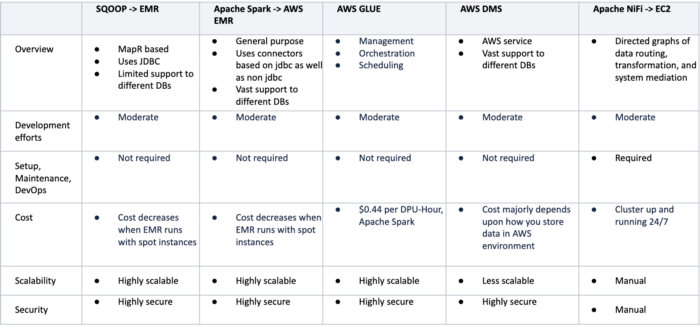
One can opt for any of the above frameworks for Realtime, Micro, and Mega batch ingestion based on the different options available and specific business requirements.
Let’s see a comparison between some of the schedulers we looked into for scheduling our jobs:
WorkFlow Engines Comparison
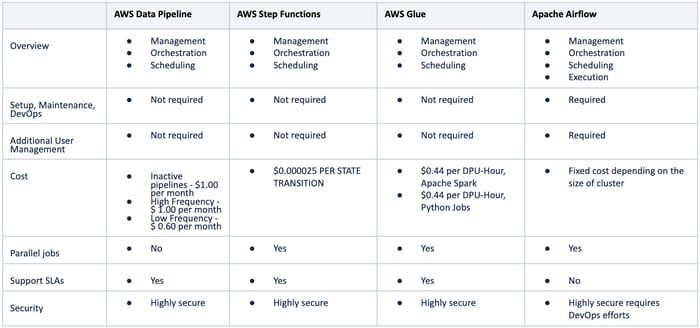
After looking into the different options available and according to business requirements, one can opt for any of the above frameworks.
Key Takeaways
This marks the end of our first blog series on building a data lake on AWS (Ingestion tier).
Let’s look into a few of the key takeaways for implementing the ingestion solution-: