In order to convert data into business value, the data have to be at the forefront of software projects. And you can’t limit the data you’re using to justify the straightforward stuff in RDBMS tables. Valuable data come in a structured form (RDBMS tables), but they also come in unstructured (text comments from reviews, logs), and semi-structured (XML) forms. The ability to process and harness all forms of data is crucial for turning them into business value. To have lasting value, all of this must be done systematically and can be extended, tested, and maintained. Having a data pipeline to crunch the data and distribute results to the business is vital.
What is a Data Pipeline?
In the general sense, a data pipeline is the process of structuring, processing, and transforming data in stages regardless of what the source data form may be. Some traditional use cases for a data pipeline are pre-processing for data warehousing, joining with other data to create new data sets, and feature extraction for input to a machine-learning algorithm.
In most real-world situations, you’re managing a forest of data that comes in different forms and sizes. Suppose we start thinking of data processing as a directed acyclic graph where each node is a processing action, and each edge is a data flow. In that case, it becomes easier to think in terms of creating complex data pipelines. Since we live in a world of Big Data, the rest of this blog post will assume we are building a Big Data pipeline. That means we’re talking about data sizes large enough that we can’t just fit all of it into a single machine’s RAM or disk.
What Technologies Will I Need?
Hadoop is synonymous with “Big Data.” Hadoop implements the MapReduce paradigm to process data in a distributed manner where data is spread across a cluster of machines. When you need more storage or computing power, you simply add another machine to the cluster. This allows for predictable and cheap scaling capabilities.
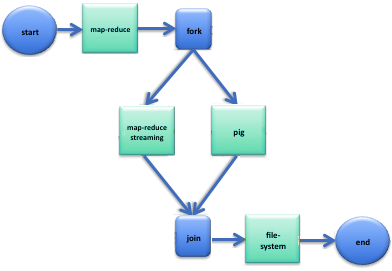
MapReduce is a very powerful paradigm, especially when it comes to parallel and distributed computing and processing. MapReduce itself can take some getting used to for application developers. Using a single MapReduce job does not solve most real problems. In the real world, a collection of MapReduce jobs are chained together so that the input to one job is the output of a previous job. This can quickly become a development and maintenance nightmare if not managed and architected properly.
The technologies that we use at our organization for creating data pipelines on our Hadoop cluster include Oozie, Hive, and Hbase. In some cases, we also use Cascading. In subsequent posts, I’ll go into more detail on each technology, but a high-level overview for each one follows below:
-
Hadoop is the MapReduce engine and the distributed file system to store the “Big Data.” It has a fairly complex architecture, but very well written API’s to write Map and Reduce jobs.
-
Hive is an abstraction of MapReduce. It uses a subset of SQL as the declarative language to express data processing. Hive SQL gets translated to a series of MapReduce jobs by the Hive engine. It’s pretty easy to find people who know the syntax of SQL, so Hive is friendly when having people with varying degrees of technical expertise access the data. It is extensible through creating custom User Defied Functions (UDF) in Java that can be invoked using Hive SQL. There is a rich library of pre-packaged UDF’s including aggregate functions, JSON, and XML processing functions.
-
Oozie is the workflow engine. It supports many flow controls and Hadoop technologies as the nodes in the workflow. Some of the supported processing actions include MapReduce, Java Main, Hive, and Pig. This allows you to build a complex workflow with a mix of technologies to build a complete data pipeline. Oozie also has a coordinator feature that allows workflows to be scheduled to run when some data become available, and it’s extensible so that you can create new processing action nodes.
-
Hbase is known as the database of Hadoop. It is a NoSQL column oriented key/value store that allows random access or fast scan (lexicographical range) queries. It uses the concept of row keys that (when designed properly in terms of your data access patterns) can power the real time use cases for getting data out. The great thing about Hbase is that it can also be used as input/output to MapReduce jobs.
-
Cascading is an application framework made for developing data applications on Hadoop. Its goals are similar to Hive, but it uses a Java API at its core. Not everything can be expressed in Hive SQL. When we encounter that situation, we prefer Cascading to plain MapReduce because the code is cleaner, more concise, and abstracts the Hadoop and MapReduce parts out nicely. Cascading uses a plumbing metaphor to describe a workflow using Taps, Sinks, Pipes, and Filters. Cascading also has a rich ecosystem and includes functional style DSL such as Scalding (Scala) and Cascalog (Clojure). The Cascading API is designed from a functional programming perspective, so the functional DSLs make it a good addition to reducing the amount of code needed to write a workflow. Cascading does not concern itself with scheduling like Oozie does and can be scheduled using cron, quartz, or [insert your favorite scheduling technology here].
The technology above works well for our “Big Data” pipeline needs. It is rare to encounter a problem that cannot be solved using Hive with custom UDF’s wrapped nicely in an Oozie workflow with a coordinator. When we do run into a situation we cannot solve using Hive, we use Cascading, and in the rarest situation, we’ll use plain MapReduce. The barrier to entry might be steep when trying this out locally or on a small dev cluster. Thankfully, many vendors give extended versions of the Hadoop technologies tested together to ensure compatibility.
In many cases, they also provide install managers and VM’s. Cloudera is one such vendor, and we use their implementation on the Amazon cloud. I will take a deep dive into each technology mentioned in this post in future posts.
Learn about Hadoop development using Cloudera VM in our blog here. To get the best data engineering solutions for your business, reach out to us at Clairvoyant.