Explaining Kafka Producer’s internal working, configurations, idempotent behavior and safe producer
Clairvoyant carries vast experience in Big data and Cloud technologies. We explore the core concepts of Apache Kafka and other big data technologies to provide the best-optimized solutions to our clients. In light of the recent performance enhancements, we have utilized the fundamental configurations in Apache Kafka producer to achieve a more optimized Kafka producer to ensure efficient execution.
In this blog, we deep-dive into Kafka producer’s architecture, its components, and configurations to help you understand the concept of Idempotent producer. We also discuss the notion of a safe producer and how it helps improve the performance of Kafka producer.
Let’s start by learning about the internal architectures of the Kafka producer and the various components involved in sending/delivering the messages to the Kafka broker (topic -partition).
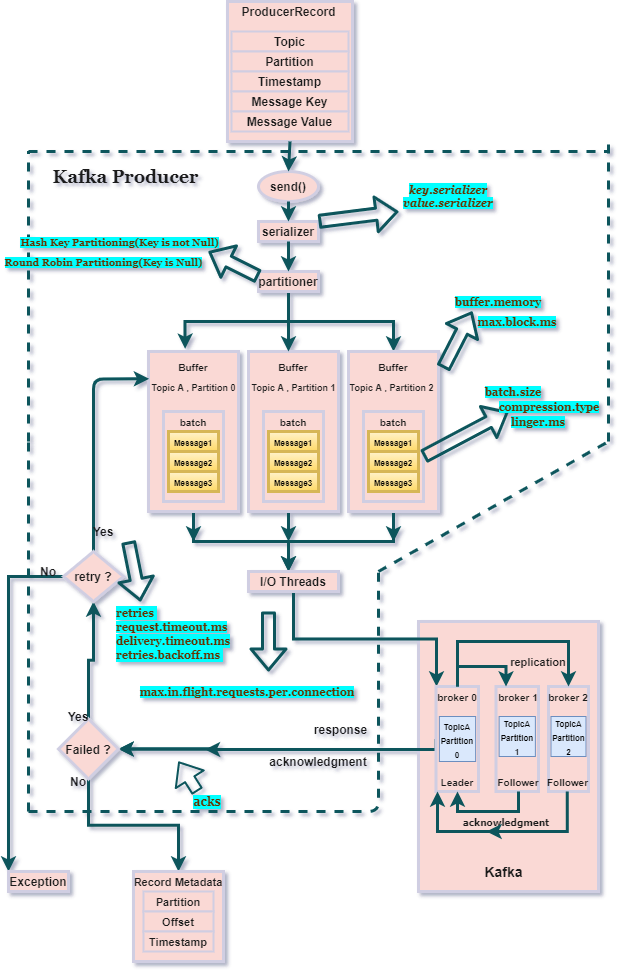 Kafka Producer Architecture and Workflow
Kafka Producer Architecture and Workflow
Components of Kafka Producer -
Send()- It adds the record to a buffer of pending records to be sent and returns immediately. This buffer of pending records helps to batch together individual records for efficiency.
Serializer- It helps serialize the key and the value objects that the user provides with their ProducerRecord into bytes.
Partitioner- Partition assignment to every ProducerRecord is done by the Partitioner. There are two types of partitioning strategies-
-
Round Robin Partitioning- This is used when the key is Null in ProducerRecord. Partitions are assigned in Round Robin fashion.
-
Hash Key-based Partitioning- This is used when ProducerRecord has a key. Partitions are determined based on the hash of the key for a particular message/value.
Note- Topic Partition can also be mentioned directly in the ProducerRecord. In that case, Round Robin and Hash Key Partitioning will not make any effect.
Buffer- A memory buffer of the unsent records is maintained by the producer for each partition. The size of the buffer can be set by the batch.size config.
I/O Threads- The background I/O thread is responsible for turning the records in the buffer into requests and transmitting them to the Kafka broker.
Let’s understand how these components work together
The process of sending messages to Kafka brokers starts with creating a ProducerRecord which has the topic-name and the message-value. Message-key and/or a partition can also be mentioned in the ProducerRecord. ProducerRecord is then sent using send().
Now, the ProducerRecord arrives at the serializer where the key and value are serialized into ByteArrays to travel/be sent over the network. Now, the ProducerRecord arrives at the partitioner.
If the partition is specified in the ProducerRecord, then the partitioner will return the same, otherwise, it will choose a partition for the message-value based on the partitioning strategy (Round Robin, Hash Key, or Custom Partitioning).
Once a partition is determined, the producer adds the message-value to a batch of records that will be sent to the same topic and partition. This batch of unsent records is maintained in the buffer-memory. Once the message arrives at the buffer memory, the send() returns and starts processing the next ProducerRecord.
A separate I/O thread is responsible for sending those batches of records as a request to the Kafka broker. When the broker successfully receives the messages, it will return a RecordMetadata object as response and it has the topic, partition, and offset of the record within the partition.
If the message fails to be received by the broker, it will return an error as a response, and the producer may retry sending the message a few more times (No. of retries) before giving up and returning the error.
Let’s analyze some of the important producer configurations
Acks — The number of acknowledgments the producer requires the leader to have received before considering a request complete. The following settings are allowed:
-
acks = 0 -> The producer will not wait for any acknowledgment from the broker. Messages will be added to the buffer and considered sent. No assurance can be given that the message was received by the broker.
-
acks = 1-> The producer will wait for the acknowledgment only from the leader broker. No guarantee can be made that the message was received by the follower broker or that the message was replicated properly.
-
acks = all -> The producer will wait for the acknowledgment from the full set in-sync replicas (leaders + followers ). This guarantees that the record was received by all the in-sync brokers and as long as at least one in-sync replica broker remains alive, the message will not be lost.
Example — Let’s consider the following scenario -
No. of brokers = 3
Replication Factor = 3
min.insync.replicas = 2 (including leader), acks = all .
As the min.insync.replica is two , we can only tolerate one broker
going down. If more than one broker goes down, the message may get
lost and won't get served to the consumer.
Also, setting acks to "1" or "all" may increase the latency since the
producer needs to wait for the ack.
Retries and Timeouts -
-
retries =(some integer value) -> It represents the number of times the producer retries sending the message whose send() got failed. However, an issue while retrying is that the order of messages/requests may change.
-
max.in.flight.requests.per.connection -> The max number of requests that can be sent on a connection before blocking. Setting this value to 1 means that only one request will be sent at a time thus preserving the message order and hence the ordering issue caused by the retry is solved.
Recommended values based on Kafka versions → max.in.flight.requests.per.connection = 1 (0.11 >= Kafka < 1.1) OR 5 (Kafka >= 1.1).
-
request.timeout.ms -> The amount of time the producer waits for the response of a request. The producer will consider the request as failed if the response is not received before the timeout elapses and begins to retry the request.
-
delivery.timeout.ms -> The upper bound on the time to consider the message delivery request a success or failure after a call to send() returns.
delivery timeout = time delay prior to sending + time to await ack + time for retries.
-
retries.backoff.ms -> The amount of time to wait before attempting to retry a failed request to a given topic partition.
For achieving 'at-least-once-delivery', it is recommended to set:- acks = all and retries = Integer.MAX_VALUE (provided the replication factor and min.insync.replicas are properly set).
Batching -
-
batch.size ->This configuration controls the default batch size in bytes. The producer will attempt to batch multiple records together into fewer requests that are being sent to the same partition.
-
linger.ms -> Instead of sending a record as soon as possible, the producer will wait for linger.ms time before sending the record. This allows multiple records to be batched together.
Batch request will be sent to the broker based on the following scenarios: 1) if batch.size worth of records arrive then a batch request will be sent. 2) if batch.size worth of records are yet to accumulate , then it will linger for a specified amount of time for more records to shows up. Also, batching and lingering can increase the latency of the record sent but can reduce the number of requests to the broker
Buffer Memory -
-
buffer.memory ->The total bytes of memory the producer can use to buffer records waiting to be sent to the server. This buffer is maintained for each topic partition.
-
max.block.ms->The configuration controls how long the Kafka producer’s send() methods will be allowed to remain blocked waiting for metadata fetch and buffer allocation.
max.block.ms = upper bound of allowed (waiting time for metadata fetch + waiting time for buffer allocation). It throws an exception if the producer is in waiting state for more than max.block.ms.
Compression -
-
compression.type -> Compression type for a batch of multiple records can be set.
default : none (i.e. no compression).
Valid values : none , gzip , snappy , lz4 or zstd.
As compression is for the full batch of data (multiple records being sent to the same partition), the efficiency of batching will also impact the compression ratio (more batching = better compression).
Compression may consume some amount of CPU cycles.
Reason for choosing the compression can be as follows —
1) It will reduce the disk footprint and use a lesser amount of disk space.
2) It will also reduce the request size which will lead to reduction in latency.
All these configurations can really help us tune the behavior of the Kafka producer to a good extent based upon our use-case requirements.
Idempotent Producer
Let’s try to understand what an Idempotent producer is and what problems it solves.
Let’s suppose your Kafka producer doesn’t receive an acknowledgment (may be due to network failure) and retries the request even though the message was committed to the broker. In such a case, the producer retries will introduce duplicates, and duplicate messages will get committed to the broker.
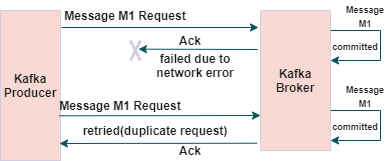 This scenario depicts the need for Idempotency
This scenario depicts the need for Idempotency
The idempotent producer solves the problem of duplicate messages and provides the 'exactly-once-delivery'.
To make the Kafka producer idempotent, we just need to enable this configuration-
-
enable.idempotence = true
Enabling idempotency will automatically set the following configurations with the default values-
-
acks = all
-
retries = Integer.MAX_VALUE
-
max.in.flight.requests.per.connection = 1 (0.11 >= Kafka < 1.1) OR 5 (Kafka >= 1.1)
Lets try to understand how it achieves idempotency
 Idempotency for a message
Idempotency for a message
For a particular session, the Kafka leader broker assigns a producer id(PID) to each producer. Also, the producer assigns a monotonically increasing sequence number (SqNo) to each message before sending it. The Kafka broker keeps track of the largest PID-SqNo combination on a per partition basis. When a lower sequence number is received, it is discarded and that’s how it avoids duplicate messages.
The configuration acks = all and retries = Integer.MAX_VALUE helps to achieve the ‘at-least-once-delivery’ of the message. Hence, that’s how an idempotent producer works and achieves the ‘exactly-once’ delivery of the message.
Note- 1) Idempotent producer can not deduplicate the application level re-sends of duplicate messages.
2) It can guarantee the ‘exactly-once’ delivery only for the messages sent within a single session.
Safe Producer
For a producer to be called safe, the following factors can be taken into consideration-
-
The messages are delivered either exactly once or at least once.
-
Order of the messages should be maintained.
-
Messages should be durable or always be available to get served to the consumer.
We can set the below producer and broker/topic configurations in order to make our producer safe:
For Kafka < 0.11 -
-
acks = all (producer level)- Ensures data is properly replicated before an ack is received.
-
min.insync.replicas = 2 (broker / topic level)- Ensures two brokers in ISR (In Sync Replicas) have the data after an ack so that if one replica goes down, another replica will be available to get served.
-
retries = Integer.MAX_VALUE (producer level)- Ensures transient errors are retried indefinitely.
-
max.in.flight.requests.per.connection=1 (producer level)- Ensures only one request is tried at any time, preventing message re-ordering in any case of retries.
For Kafka >= 0.11 -
-
enable.idempotence =true (producer level)
Implies — acks = all , retries = Integer.MAX_VALUE , max.in.flight.requests.per.connection = 1 (0.11 >= Kafka < 1.1) OR 5 (Kafka >= 1.1)
-
min.insync.replicas = 2 (broker / topic level)
The above mentioned configurations for safe producer are for the ideal scenarios; where we are not considering real world scenarios which may impact the overall performance like in the below situations-
1) application level message re-sends (duplicates).
2) Leader broker goes down along with the follower broker (No replicas to get served to the consumer).
3) Buffer memory leaks (Not enough buffer memory for batching).
4) Latencies due to network bandwidth and/or request sending/ processing speed of the servers, etc.
Conclusion
We learned the various producer configurations and their impacts on the behavior of Kafka Producer. We also discussed Idempotent and safe producer which helps improve the performance of the Kafka producer.
We hope this blog will help you make better decisions while configuring the Kafka producer. Learn how to manage Apache Kafka pragmatically with our blog here.
To get the best data engineering solutions, reach out to us at Clairvoyant.
Thank you for reading till the end. Hope you enjoyed it!
References
https://kafka.apache.org/27/javadoc/index.html?org/apache/kafka/clients/producer/KafkaProducer.html
https://kafka.apache.org/27/javadoc/index.html?org/apache/kafka/clients/producer/KafkaProducer.html