The fastest way to analyze Big Data in the Cloud
Dataproc is a managed Spark and Hadoop service in Google Cloud that lets you take advantage of open-source data tools for batch processing, querying, streaming, and machine learning. Dataproc automation helps you create clusters quickly, manage them easily, and save money by turning clusters off when you don’t need them.
Dataproc helps organizations harness their data and use it to identify new opportunities. That, in turn, leads to more innovative business moves, more efficient operations, higher profits, and happier customers.
Dataproc uses Hive and Spark independently to analyze Big Data. Apache Hive is a data warehousing tool built on the top of Hadoop to summarize Big Data. It uses HQL (Hive Query language), similar to SQL, to process data. HQL is fast, scalable, and extensible. Apache Spark is a lightning-fast unified analytics engine for big data and machine learning that overcomes the performance issues faced by MR and Tez engines.
Setting Spark as an execution engine for Hive:
By default, in a Dataproc cluster, the Hive execution engine is set to Tez. We can also set the Hive execution engine to Spark. However, it will not work. We have to update some configurations to make this work. If we set Spark as an execution engine for Hive, it would become the fastest analytics solution for Big data.
Here are the configurations that we need to do:
Set spark_shuffle in addition to mapreduce_shuffle in yarn-site.xml :
Property: yarn.nodemanager.aux-services
Value: mapreduce_shuffle, spark_shuffle
Restart the Resource Manager service on the Master node and the Nodemanager Service on Worker nodes.
Start the Spark Thrift server on port 10010 on the Master node of the Dataproc cluster.
sudo -u spark HIVE_SERVER2_THRIFT_PORT=10010
/usr/lib/spark/sbin/start-thriftserver.sh
Once you start Spark Thrift server, let's connect to Hive using JDBC URL :
beeline -u “jdbc:hive2://localhost:10010/``”?hiveconf=hive.execution.engine=spark
Note:
-
Hiveserver2 runs on Port 10000 (for Hive Queries)
-
Spark Thrift server runs on port 10010 (for Hive on Spark Queries)
Let us run Hive query using Spark as an execution engine:
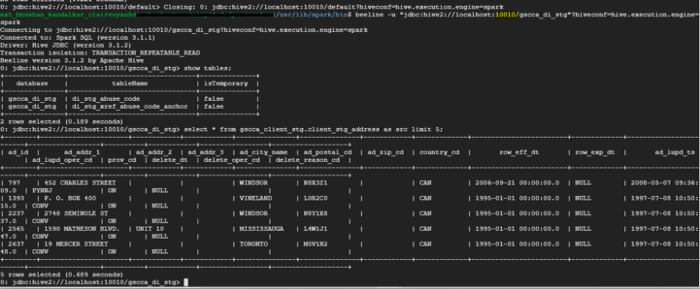
That’s it! You have successfully executed Hive queries on the Spark execution engine.
You can also use this JDBC URL in the BI tool of your choice to run Hive queries using the Spark execution engine.
Also, check out our blog about Bucket Map Join in Hive here. Reach out to us at Clairvoyant for all your Cloud computing services requirements.