This article will help you increase the Hive-query optimization using bucket map join.
Clairvoyant aims to provide the best-optimized solutions to its clients. We use well-designed tables and queries to significantly improve query execution performance and reduce processing costs. The objective of this blog is to understand more about Bucket Map Join in Hive and how it helps optimize query performance.
1. Introduction
Hive is trying to embrace CBO (Cost Based Optimizer) in its latest versions, and joining tables is a major part of it. Understanding joins, their best practices, and use cases are a few of the key factors of Hive performance tuning.
In normal join, the reducer gets overloaded in MapReduce framework if the tables are large. It receives all the data from the join key and value basis, and the performance also degrades as more data is shuffled. So we use the Hive Bucket Map Join feature when we are joining tables that are bucketed and joined on the bucketing column.
2. How does Bucketing help in Hive Join?
In bucketing, the data at the storage level is distributed in buckets. Each bucket is expected to hold/contain certain rows based on the bucketing key/column. Here we can process the portion of data individually on the mapper side of a Hive job. The ‘CLUSTERED BY’ command is used in Hive while creating bucketed tables. It makes query processing easy and efficient in terms of performance while joining large bucketed tables.
3. How does Bucket Map Join work?
In Hive, Bucket map join is used when the joining tables are large and are bucketed on the join column. In this kind of join, one table should have buckets in multiples of the number of buckets in another table. For example, if one Hive table has 3 buckets, then the other table must have either 3 buckets or a multiple of 3 buckets (3, 6, 9, and so on).
If the above condition is satisfied, then the joining operation of the tables can be performed at the mapper side only; otherwise, an inner join is performed. Here, only the required buckets are fetched onto the mapper side but not the complete data of the table. It means that only the matching buckets of small tables are replicated onto each mapper while joining. By doing this, the efficiency of the query is improved drastically. In a bucket map join, data is not sorted. If we need data to be sorted, we should go for Sort Merge Bucket Map join.
4. Use Case of Bucket Map Join
When the joining table sizes are big, a normal join or a map join is not good. So in these scenarios, we go for the Bucket Map Join feature.
5. Bucket Map Join query execution
As an example, let’s say there are two tables, table1, and table2, and both tables’ data is bucketed using the ‘emp_id’ column into 8 and 4 buckets. It means bucket1 of table1 will contain rows with the same ‘emp_id’ as that of bucket1 of table2. If we perform join on these two tables on the ‘emp_id’ column, and if it is possible to send bucket1 of both the tables to a single mapper, we can achieve a good amount of optimization. This is exactly done by bucketed map join in executing Hive jobs. Bucket Map Join is not the default behavior and is enabled by the following parameter:
hive> set hive.optimize.bucketmapjoin = true
Following are the commands used for creating bucketed tables table1 and table2:
hive> set hive.enforce.bucketing = true;
hive> CREATE TABLE IF NOT EXISTS table1 (emp_id int, emp_name string, emp_city string, gender String) clustered by(emp_id) into 8 buckets row format delimited fields terminated BY ‘,’;
hive> CREATE TABLE IF NOT EXISTS table2 (emp_id int, job_title string) clustered by(emp_id) into 4 buckets row format delimited fields terminated BY ‘,’;
Now, we load the records into both the tables
hive> load data local inpath ‘/relativePath/data1.csv’ into table table1;
hive> load data local inpath ‘/relativePath/data2.csv’ into table table2;
hive> set hive.optimize.bucketmapjoin=true;
Let us perform a bucketed map join on their ‘emp_id’ as shown below and verify the time taken for the same
hive> SELECT /*+ MAPJOIN(table2) */ table1.emp_id, table1.emp_name, table2.job_title FROM table1 JOIN table2 ON table1.emp_id = table2.emp_id;
Where:
table1 is the bigger or larger table
table2 is the smaller table than the table1
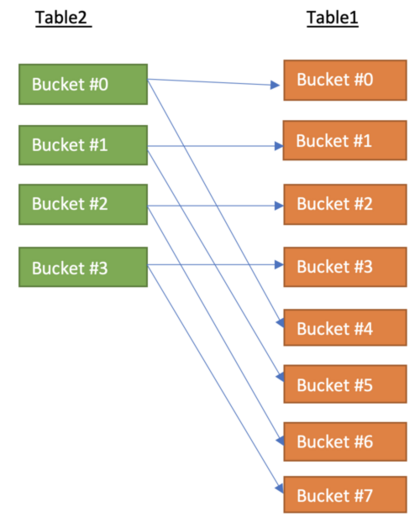
%20retrieves%20the%20only%20corresponding%20bucket%20of%20Table1%20(smaller%20table)%20to%20complete%20the%20join%20task..png) Each mapper processing a file split from Table2 (larger table) retrieves the only corresponding bucket of Table1 (smaller table) to complete the join task.
Each mapper processing a file split from Table2 (larger table) retrieves the only corresponding bucket of Table1 (smaller table) to complete the join task.
6. BucketMapJoin on different Hive execution engines
In the hive-on-mr (using MapReduce engine) implementation, bucket map join optimization has to depend on the map join hint ( /*+ MAPJOIN(table2) */).
While in the hive-on-tez (using TEZ engine) implementation, joining can be automatically converted to bucket map join if certain conditions are met, such as:
(i) The optimization flag hive.convert.join.bucket.mapjoin.tez is ON
(ii) All the joining tables are bucketed and each small table’s number of buckets can divide the big table’s number of buckets.
(iii) bucketing column == joining column.
In the hive-on-spark (using Spark engine) implementation, it is ideal to have Bucket map join auto-conversion support. When all the required criteria are met, a join can be automatically converted to a Bucket map join.
7. Constraints to use bucket map join
We can use Bucket Map Join in Hive only when the tables are bucketed and joined on the bucketed column. Also, the number of buckets in one table must be equal or a multiple of the number of buckets in the other table of the join.
Conclusion
We have seen content regarding the Apache Hive Bucket Map Join feature, how to use it with an example, use cases, tips, and constraints of Bucket Map Join. I hope this blog helps you enhance your knowledge on Hive.
To learn more about Running Hive Jobs using Spark Execution Engine on Google Cloud Dataproc Cluster, head to our blog post here. For all your Data engineering solutions requirement, contact us at Clairvoyant.