Real time replication tool for heterogeneous IT platforms. This is the second part of a series of blogs to configure golden gate to replicate data from mysql to hive.

In this blog we are going to focus on replicating data onto HDFS from the local edge node using Oracle Golden Gate big data adapters. The data on the edge node is in the form of trail files which has been transferred over the network by our pump process configured in our previous blog. Our target database (database used for replication) is Hive which is on a six node hadoop cluster using HortonWorks distribution of hadoop.
NOTE: Deploying a hadoop cluster is beyond the scope of this blog.
Oracle GoldenGate and Big Data:
We are very familiar with the three V’s of big data:
-
Variety
-
Velocity and
-
Volume
The major challenges of a big data ETL engineer is harvesting data from multiple data sources. OGG being source and target agnostic can provide great advantage in this aspect providing engineers to easily harvest data from diverse sources and performing transformations on them before moving the data into Big Data reservoirs.
Another important aspect of Oracle Golden Gate is real time data replication and high availability. This makes OGG a great tool for the business, playing a critical role to achieve the above mentioned aspects.
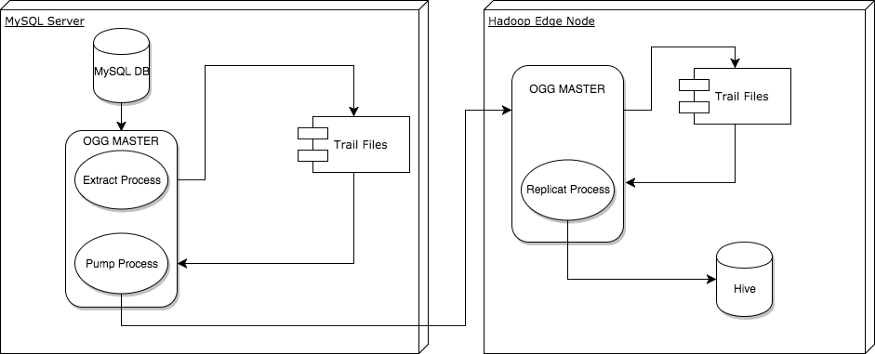 Architecture Diagram
Architecture Diagram
Installing Golden Gate on Hadoop:
Environment Overview:
-
OS: RHEL 7
-
HortonWorks Distribution of Hadoop
-
GoldenGate 12.2.0.1.170221
-
Hive 1.2.1000.2.5.3.0–37
The version of OGG we have used is not directly available on the download.oracle.com but edelivery.oracle.com. Download the zip file and place the tar file from the unzipped folder into /u01/oggbd/. This will be the home directory of OGG where we un-tar the file.
As we have mentioned earlier the manager process is the brain of OGG and needs to run on both the source and target. We will follow the same steps to configure the manager process on the target as well.
-bash-4.2$ ./ggsci Version 12.2.0.1.160419 OGGCORE_12.2.0.1.0OGGBP_PLATFORMS_160430.1401 Linux, x64, 64bit (optimized), Generic on Apr 30 2016 16:21:34 Operating system character set identified as UTF-8. Copyright (C) 1995, 2016, Oracle and/or its affiliates. All rights reserved. GGSCI (targetserver) 1> create subdirs Creating subdirectories under current directory /u01/oggbd/ Parameter files /u01/oggbd/dirprm: created Report files /u01/oggbd/dirrpt: created Checkpoint files /u01/oggbd/dirchk: created Process status files /u01/oggbd/dirpcs: created SQL script files /u01/oggbd/dirsql: created Database definitions files /u01/oggbd/dirdef: created Extract data files /u01/oggbd/dirdat: created Temporary files /u01/oggbd/dirtmp: created Credential store files /u01/oggbd/dircrd: created Masterkey wallet files /u01/oggbd/dirwlt: created Dump files /u01/oggbd/dirdmp: created GGSCI (targetserver) 2> edit param mgr port 7809 autorestart extract * dynamicportlist 7810-7820 GGSCI (targetserver) 3> start mgr Manager started. GGSCI (targetserver) 4> info all Program Status Group Lag at Chkpt Time Since Chkpt MANAGER RUNNING GGSCI (targetserver) 2> edit params ./GLOBALS ALLOWOUTPUTDIR /u01/oggbd/trailfiles/
One important configuration that needs to be set is ALLOWOUTPUTDIR in ./GLOBALS. This is an important parameter that needs to be set for the pump to write data to a custom location. If this is not set the pump process might fall into the ABENDED/STOPPED state.
Configuring the Replication Process:
-
One the main files which needs to be configured and provides control over data replication is the hdfs property file. This file is created and places in the dirprm directory in OGG home. Here is a sample hdfs.props file in my environment.
[targetserver]# cat hdfs.props gg.handlerlist=hdfs gg.handler.hdfs.type=hdfs gg.handler.hdfs.includeTokens=false gg.handler.hdfs.maxFileSize=1g gg.handler.hdfs.rootFilePath=/tmp/ogg1 gg.handler.hdfs.fileRollInterval=0 gg.handler.hdfs.inactivityRollInterval=0 gg.handler.hdfs.fileSuffix=.txt gg.handler.hdfs.partitionByTable=true gg.handler.hdfs.rollOnMetadataChange=true gg.handler.hdfs.authType=none gg.handler.hdfs.format=delimitedtext gg.handler.hdfs.format.includeColumnNames=true gg.handler.hdfs.mode=tx goldengate.userexit.timestamp=utc goldengate.userexit.writers=javawriter javawriter.stats.display=TRUE javawriter.stats.full=TRUE gg.log=log4j gg.log.level=INFO gg.report.time=30sec gg.classpath=dirprm/:/u01/oggbd/ggjava/resources/lib*:/usr/hdp /current/hadoop-client/client/*:/etc/hadoop/conf javawriter.bootoptions=-Xmx512m -Xms32m -Djava.class.path=.: ggjava/ggjava.jar:./dirprm
Note: The class path contains the hadoop home directory and other hadoop packages. This can be different for different distributions of hadoop.
As you can see there are a lot other options as well so highly recommend reading the official docs.
2. Just like we have configured a EXTRACT process in this case we create a REPLICAT process for which we create a param file.
GGSCI (targetserver) 5> edit param EREPLICAT REPLICAT EREPLICAT SETENV (JAVA_HOME='/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.91 -2.6.2.3.el7.x86_64/jre/') DDL include all TARGETDB LIBFILE libggjava.so SET property=dirprm/hdfs.props REPORTCOUNT EVERY 1 MINUTES, RATE GROUPTRANSOPS 10000 MAP clairvoyant_test.*, TARGET clairvoyant_test.*;
Instead of the replicat connecting to the target database the replicat is calling out to a library for each record in the trail file. The libggjava.so file should be located in the same directory as ggsci.
3. Register the process and start it
GGSCI (targetserver) 1> add replicat ereplicat, exttrail /u01/oggbd/trailfiles/bb REPLICAT added. GGSCI (targetserver) 2> start replicat ereplicat Sending START request to MANAGER ... REPLICAT EREPLICAT starting
If your REPLICAT status is ABENDED/STOPPED or have another issue that you seem you can find out why there is a fair chance it has something to do with your classpath and not being able to find all the required jars.
Once the process has started the data gets written to HDFS in the form of text files. We can create external hive tables over the directory specified in our hdfs.props (gg.handler.hdfs.rootFilePathfile).
Here is an example as to how to create an external table in hive for our data.
CREATE EXTERNAL TABLE USER ( EMP_ID INT, NAME STRING, DOB DATE, SALARY INT, ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\u0001' LINES TERMINATED BY '\n' LOCATION '/tmp/ogg1' ;
With the Hive table created we can go head and query the table.
hive> select * From user; OK I 1 kt 2000-01-08 1000 U 1 kt 2000-01-08 1500 Time taken: 0.145 seconds, Fetched: 2 row(s)
You will notice the first columns have an I and a U. I means INSERT and U means UPDATE. This column can be used to create views on top of the hive table to provide updated data to the end users.
Overall Oracle Golden Gate is a great tool which provides businesses to analyze and act upon information and making decisions in real or near-real time. The modular architecture of the platform also allows engineers to configure it in various topologies as well. Configuring it is also fairly simple as long as we get a few critical configuration steps correctly.
To get the best data engineering solutions for your business, reach out to us at Clairvoyant.