Real time replication tool for heterogeneous IT platforms. This is the first part of a series of blogs to configure golden gate to replicate data from mysql to hive.
Oracle Golden Gate is an enterprise software tool built for realtime data replication and integration across multiple heterogeneous platforms. It enables fast, real time transactional data, data replication, data transformations from a single source or multiple sources to a single target or multiple targets in real time, with low overhead from operational to analytical enterprise systems.
There are various datasources that OGG can be integrated with:
-
Oracle and non-Oracle Databases such as MySQL, IBM DB2, MS SQL, Sybase.
-
Big Data reservoirs such as hive, impala, hdfs, hbase etc.
-
Flat files, CSVs, TSVs, JSON and any other unstructured data files.
-
JMS and Java API.
As we have seen above the source and target agnostic nature of OGG offers a great advantage in this aspect which allows ETL engineers to easily harvest data from various sources into data reservoirs.
Here are a few use cases of OGG:
-
IT Teams and ETL developers can feed OLAP systems with real-time data from OLTP systems without unduly affecting database and application performance.
-
One of the very common use case is migration of data from oracle databases to non-oracle databases and vice versa.
-
To create a secondary database that can be used during updates to the production database. Hence, providing continued availability to the end users.
-
One of the major challenges of creating a big data reservoir is pulling data from various formats and sources. OGG provides easy integration to all these sources plays a major role in data replication onto the hadoop platform.
In this blog we are going to focus on a specific use case of integration and replication of mysql transactions into hadoop and eventually query the data using Hive.
Before we deep dive into the configurations and setting up the environment for using Golden Gate here are the three main components of our system.
-
Source: The server where the data source is located at.
-
Target: The server where the target data sink is located at.
-
Manager Process: Manager is like a brain to Golden Gate and acts like a controller for all the processes across the servers. It runs on both the source and the target servers.
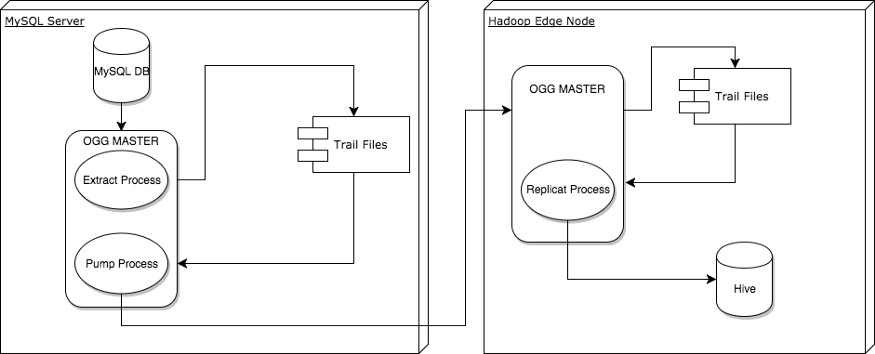 Architecture Diagram of different processes involved
Architecture Diagram of different processes involved
This is a high level architecture of the replication process we are going to follow. As you can see there are three processes that need to be configured in Golden Gate for data replication from mysql to hive.
-
Extract Process: This is the process which is configured to extract data from mysql and replicate it to a destination on the local file system as trail files.
-
Pump Process: This is the process which is configured to push the trail files from the mysql server to the hadoop edge node. Configuration of these two processes is covered in this blog post.
-
Replication Process: This is the process which is configured to replicate the trail files that have been pushed to the hadoop edge node to text files onto hdfs over which there can be external hive tables that can be created. Configuration of this process is covered in the third part of the blog post.
Before getting into more details about configuring each of these processes — creating a hadoop cluster (we have a hortonworks distribution of hadoop on AWS) and creating an EC2 instance with mysql deployed on it are beyond the scope of this blog and are the prerequisites.
Installing Golden Gate on source:
Requirements of MYSQL engine:
-
Storage engine should be InnovDB.
-
DB privilege for the DB user from Oracle GoldenGate extract process. This user needs to login to the MySQL DB with
1. access INFORMATION_SCHEMA database.
2. select any table
-
MySQL configuration
binlog_format = ROW log-bin = <path_to_log_bin> max_binlog_size = <nMB>
OS Requirements:
-
>1 GB disk space for installation/trail file. If more trail files are being kept, increased disk space is needed.
-
OS privileges for the OS user that runs Oracle Golden Gate(OGG) extract process. The best way is to install OGG as the mysql user, and let it run as the mysql user.
Installation:
-
Create the following directory owned by the mysql user:
mkdir -p /goldengate/mysql/12_2 # This is the home directory of OGG chown -R mysql:mysql /goldengate/mysql/
-
Download the OGG for mysql and place it in /goldengate/mysql/12_2
$ cd /goldengate/mysql/12_2 $ ls -la -rw-rw-r--. 1 mysql mysql 698275840 Sept 17 21:58 ggs_Linux_x64_MySQL_64bit.tar $ tar -xvf ggs_Linux_x64_MySQL_64bit.tar
-
This tar file explodes and you have all the required libraries in this directory, which in fact is the home directory for OGG.
-bash-4.2$ ./ggsci Oracle GoldenGate Command Interpreter for MySQL Version 12.2.0.1.170221 OGGCORE_12.2.0.1.0OGGBP_PLATFORMS_170123.1033 Linux, x64, 64bit (optimized), MySQL Enterprise on Jan 23 2017 13:00:10 Operating system character set identified as UTF-8. Copyright (C) 1995, 2017, Oracle and/or its affiliates. All rights reserved. GGSCI (sourceserver) 1> create subdirs Creating subdirectories under current directory /goldengate/mysql/122 Parameter files /goldengate/mysql/122/dirprm: created Report files /goldengate/mysql/122/dirrpt: created Checkpoint files /goldengate/mysql/122/dirchk: created Process status files /goldengate/mysql/122/dirpcs: created SQL script files /goldengate/mysql/122/dirsql: created Database definitions files /goldengate/mysql/122/dirdef: created Extract data files /goldengate/mysql/122/dirdat: created Temporary files /goldengate/mysql/122/dirtmp: created Credential store files /goldengate/mysql/122/dircrd: created Masterkey wallet files /goldengate/mysql/122/dirwlt: created Dump files /goldengate/mysql/122/dirdmp: created
-
Configure the manager process of OGG to run on port 7809 (you can use a port of your choice) and auto restart for all the extract processes.
GGSCI (sourceserver) 2> edit param mgr port 7809 autorestart extract * GGSCI (sourceserver) 3> start mgr Manager started. GGSCI (sourceserver) 4> info all Program Status Group Lag at Chkpt Time Since Chkpt MANAGER RUNNING
Now we have OGG installed on the source side with the manager running on port 7809.
Configuring the extract process:
In this process we have configure an extract named USEREXTRACT which writes the trail files to /goldengate/trailfiles directory.
All the trail files have the same naming convention of two trail letters and 9 digits following it, starting with 000000000.
Configuration:
1. Create the folder for the trail files to write into on the local server
mkdir -p /goldenage/trailfiles # This is the home directory of OGG chown -R mysql:mysql /goldengate/trailfiles
2. Prepare extract parameter file. In this example, the extract process will extract data from the clairvoyant_test.user and clairvoyant_test.user_info tables. The extracted data will be written to local trail files labeled as “aa”:
GGSCI (sourceserver) 5> edit param USEREXTRACT extract USEREXTRACT SETENV (MYSQL_HOME='/var/lib/mysql/') SETENV (MYSQL_UNIX_PORT='/var/lib/mysql/mysql.sock') SOURCEDB clairvoyant_test@localhost, userid ggs, password clairvoyant tranlogoptions altlogdest /var/lib/mysql/mysql-bin.index reportcount every 10000 records, rate exttrail /goldengate/trailfiles/aa table clairvoyant_test.user; table clairvoyant_test.user_info, colsexcept (cc,ssn);
Notice this parameter file closely. This is the only configuration that we will be doing for the extract process so please go through the documentation of OGG to know about these options in more detail. Here I will discuss about two parameters that are very important even during the configuration of mysql.
As mentioned earlier the pre requisites of mysql instance we should also configure our mysql transactions to write to /var/lib/mysql/mysql-bin.index. This is the place from where our OGG pulls the data from to extract and write it as trail files.
Another useful discussion point is extracting based on columns for certain tables. USER_INFO table contains sensitive information such as credit card information and ssn of a user which in certain use cases are not required to be replicated or extracted for later processing of the data. These columns can be excluded by using COLSEXCEPT.
3. Register the process and start it
GGSCI (sourceserver) 6> add extract USEREXTRACT tranlog begin now EXTRACT added. GGSCI (sourceserver) 7> add exttrail /goldengate/trailfiles/aa extract USEREXTRACT EXTTRAIL added. GGSCI (sourceserver) 13> start USEREXTRACT Sending START request to MANAGER ... EXTRACT USEREXTRACT starting GGSCI (sourceserver) 14> info USEREXTRACT EXTRACT ETEST Last Started 2017-08-23 00:00 Status RUNNING Checkpoint Lag 00:06:24 (updated 00:00:01 ago) Process ID 26270
4. Check out the trail files that have been generated.
ls -la /goldengate/trailfiles/ total 4 -rw-r-----. 1 mysql mysql 3126 Sep 15 18:31 aa000000000
NOTE: If for some reason you do not see the trailfiles or the STATUS of the USEREXTRACT process is in ABENDED/STOPPED state, view report USEREXTRACT will help you debug the issue.
There are tools like logdump which help to read these trail files and check the validity of these trail files.
Configuring the pump process:
The extract process which writes to a local trail file has been configured and is up and running. Now we will see how to configure, add, and start the data pump. This is another Extract process. It reads the records in the source trail written by the Local Extract, pumps or passes them over the network to the target, and creates a target or remote trail.
Configuration:
-
Configure the data pump param file
GGSCI (sourceserver) 1> edit params epump extract epump PASSTHRU RMTHOST targetserver, MGRPORT 7809, TIMEOUT 30 RMTTRAIL /u01/oggbd/trailfiles/bb TABLE clairvoyant_test.*;
Some parameters in this param file:
PASSTHRU parameter on the data pump if you aren’t doing any filtering or column mapping and your source and target data structures are identical. Using PASSTHRU improves performance by allowing GoldenGate to bypass looking up any table definitions from the database or the data-definitions file.
RMTRAIL is the location on the target server where you want the data to be transferred to over the network.
RMTHOST is the parameter set to define the target server. The data pump to work the OGG should also be configured on the target server too.
2. Register the process and start it
GGSCI (sourceserver) > ADD EXTRACT epump, EXTTRAILSOURCE /goldengate/trailfiles/aa GGSCI (sourceserver) > ADD RMTTRAIL /u01/oggbd/trailfiles/bb, EXTRACT epump, MEGABYTES 100
3. Start the pump process
GGSCI (sourceserver) > START EXTRACT epump
Go to the target server which is our hadoop edge node and check the directory /u01/oggbd/trailfiles/bb*.
This sums up the configurations on the source node. We will configure the target node to read those trail files and place that into hdfs and query the data using hive in the next blog post.
Oracle GoldenGate is an enterprise software tool built for realtime data replication and integration across multiple heterogeneous platforms.It enables fast, real time transnational change of data capture, data replication, data transformations from operational to analytical enterprise systems.
Read the second blog in this series, Oracle golden gate for Big Data - II here. To get the best data engineering solutions for your business, reach out to us at Clairvoyant.