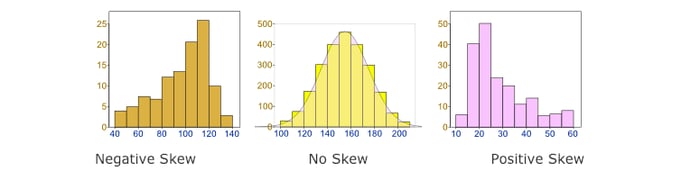
What is skewed Data? Skewness is the statistical term, which refers to the value distribution in a given dataset. When we say that there is highly skewed data, it means that some column values have more rows and some very few, i.e., the data is not properly/evenly distributed. Data skewness affects the performance and parallelism in any distributed system. You can learn more about the use cases related to skewed data statistics here.
Joining two or more large tables having skewed data in Spark
Joining two or more large tables having skew data in Spark
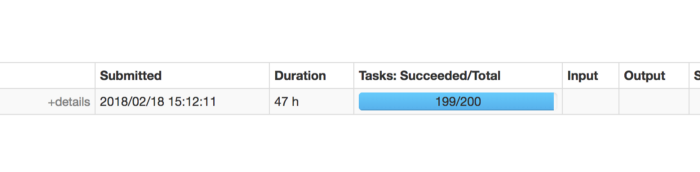
While using Spark for our pipelines, we were faced with a use-case where we were required to join a large (driving) table on multiple columns with another large table on a different joining column and condition. The Spark join column was highly skewed, and the other table was an evenly distributed data frame. Both of these data frames were fairly large (millions of records). The job was getting stuck at the last stage (say at 399/400 steps) and stayed that way for 3 to 4 hours post, which threw an error that read- Caused by: org.apache.spark.shuffle.FetchFailedException: Too large frame: 7498008366. On the Spark Web App UI, we saw this-
-- Sample query where we are joining on highly null columns
select *
from order_tbl orders left join customer_tbl customer
on orders.customer_id = customer.customer_id
left join delivery_tbl delivery
on orders.delivery_id = delivery.delivery_id
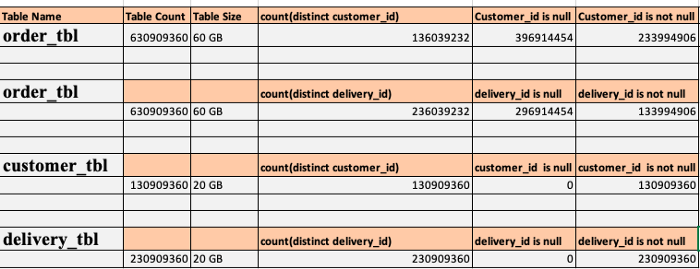
Below is the Table and Column Statistics :
Spark Issue Skewed Data
Since the driving table has null values and can’t filter null records before joining, we need all the records from the deriving table, i.e., all null records from the driving table. We may notice that it progresses to 199 tasks quickly and then gets stuck on the last task.
Reason for the above behavior: We have commanded Spark to join two DataFrames — TABLE1 and TABLE2. When Spark executes this code, it performs the default Shuffle Hash Join internally (Exchange hash partitioning).
+- Exchange hashpartitioning(delivery_id#22L, 400)
+- *(6) Project [delivery_id#22L]
n this process, Spark hashes the join column and sorts it. It then tries to keep the records with the same hashes in both partitions on the same executor so that all the null values of the table go to one executor, and Spark gets into a continuous loop of shuffling and garbage collection with no success.
Solution
We need to divide the table into two parts. The first part will contain all the rows that don’t have a null key, and the second part will contain all the data with no null values.
CREATE TABLE order_tbl_customer_id_not_null as select * from order_tbl where customer_id is not null; CREATE TABLE order_tbl_customer_id_null as select * from order_tbl where customer_id is null;
We need to change/rewrite our ETL logic to perform a left join with the not_null table and execute a union with the null column as ultimately null keys won’t participate in the join. Hence, we can avoid a shuffle and the GC Pause issue on the table by following this technique with large null values.
--Rewrite query
select orders.customer_id
from order_tbl_customer_id_not_null orders left join customer_tbl customer
on orders.customer_id = customer.customer_id
union all
select ord.customer_id from order_tbl_customer_id_null ord;
Hope this blog helps you understand the issue in Spark skew. In case of any queries, please leave a comment below, and we will be happy to address it. Don’t forget to check out our Data Engineering solutions for all your business requirements. Happy coding.