How to take benefit of Apache Arrow while converting Python pandas DataFrame into Spark DataFrame or vice-versa
If you are a Spark user who prefers to work in Python and Pandas, join us as we explore what Apache Arrow is and how it helps us speed up the execution of PySpark applications which deals with Python pandas.
Before moving further, let’s familiarize ourselves with some basic concepts of Apache Arrow.
What is Apache Arrow?
As per the official definition — Apache Arrow is a cross-language development platform for in-memory data. It specifies a standardized language-independent columnar memory format for flat and hierarchical data, organized for efficient analytic operations on modern hardware. It also provides computational libraries and zero-copy streaming messaging and interprocess communication. Languages currently supported include C, C++, C#, Go, Java, JavaScript, MATLAB, Python, R, Ruby, and Rust.
In other words, we can say that Apache Arrow is the mediator between cross-language components (listed in the above picture) like reading Spark DataFrames and writing that into such stores as Cassandra or HBase without worrying about the conversion that might include enormous inefficient serialized and deserialized data structures. Thus, Apache Arrow is useful for providing a seamless and efficient platform for sharing data across different platforms.
What is Apache PyArrow?
In general terms, it is the Python implementation of Arrow. PyArrow library provides a Python API for the functionality provided by the Arrow libraries, along with tools for Arrow integration and interoperability with pandas, NumPy, and other software in the Python ecosystem.
Apache PyArrow with Apache Spark
As mentioned above, Arrow is aimed to bridge the gap between different data processing frameworks. One place where the need for such a bridge is data conversion between JVM and non-JVM processing environments, such as Python. We all know that these two don’t play well together.
As we know Spark does a lot of data transfer between the Python and JVM, PyArrow will be mainly useful to Python users that work with NumPy/Pandas data and can help in accelerating the performance of PySpark applications.
This blog will take a more detailed look at what is the problem with existing pandas conversion, how PyArrow is implemented in Spark, how to enable this functionality in Spark and why it leads to such a dramatic speedup with sample examples.
Why do we need PyArrow? What is the problem with existing Pandas/Spark conversion without PyArrow?
While working on PySpark, a lot of people complain about their application running Python code is very slow and that they deal mostly with Spark DataFrame APIs which is eventually a wrapper around Java implementation. Also at the same time, they say Scala is must faster with the same code. So in such scenarios, users often have to decide between Scala or Python as Scala is native to the JVM and Python has rich libraries that are popular among data scientists but are less efficient to run on the JVM. To tackle such issues, Python-based programming community introduced PyArrow which dramatically accelerates processing on the JVM
In Spark, the data processing is very fast as long as data is in the JVM, but once we need to transfer out that data to a Python process, it will be a huge bottleneck and the application will slow down because Spark uses the Python Pickle format internally for serializing and deserializing a Python object. This is not known to be efficient and is kind of a bulky serialization format.
Let’s start by looking at the simple example code(running in Jupyter Notebook) that generates a Pandas Dataframe and then creates a Spark Dataframe from a Pandas Dataframe first without using Arrow:
import numpy as np
import pandas as pdspark = SparkSession\
.builder\
.appName(“PyArrow_Test”)\
.enableHiveSupport()\
.getOrCreate()# Creating two different pandas DataFrame with same data
pdf1 = pd.DataFrame(np.random.rand(100000, 3))
pdf2 = pd.DataFrame(np.random.rand(100000, 3))# Let’s test the conversion of Pandas DataFrames to Spark DataFrames first without modifying anything and then allowing PyArrow.%time df1 = spark .createDataFrame(pdf1)

Running the above code locally in my system took around 3 seconds to finish with default Spark configurations. Here in the code shown above, I’ve created two different pandas DataFrame having the same data so we can test both with and without enabling PyArrow scenarios.
How does the above piece of code internally convert Pandas Dataframe into Spark DataFrame without enabling PyArrow?
- Initially, we generated a 3D array of random 100,000 records from NumPy. Then this NumPy data was converted to a Pandas DataFrame. This served as our input into Spark
- Now our task was to create a Spark Dataframe. I created a Spark DF from a Pandas DF with a spark’s createDataFrame(pandas_df) function
- Here, createDataFrame() uses pandas’s to_records() function to convert a pandas.DataFrame to a Spark Dataframe by creating a list of records from pandas.DataFrame which in turn creates a list of numpy records
- The above step also corrected the data types of fields in a record, to ensure that they were properly loaded into Spark. Then the list of numpy records was converted to python lists
- Afterward, the Python list was converted into a Java RDD by performing a heavy serialization (using Python Pickle) on Python objects to transfer this data to JVM. This process discards schema metadata so there will be one more iteration over the data to infer the type information
- As the last step, the Java RDD was converted to Spark DataFrame
This really wasn’t much data, but it was still extremely slow. The reason is that Spark iterates through each row of data and performs the conversion from Python to Java for each value with type checking where most of the time is consumed in data serialization.
Let’s see what Arrow can do to improve it.
How to use PyArrow in Spark to optimize the above Conversion
The above approach of converting a Pandas DataFrame to Spark DataFrame with createDataFrame(pandas_df) in PySpark was painfully inefficient. Now we will run the same example by enabling Arrow to see the results.
PyArrow Installation — First ensure that PyArrow is installed. There are two ways to install PyArrow. If we install using pip, then PyArrow can be brought in as an extra dependency of the SQL module with the command pip install pyspark[sql]. Otherwise, you must ensure that PyArrow is installed and available on all cluster nodes. The currently supported version; 0.8.0, can be installed using pip or conda from the conda-forge channel. Read through the PyArrow installation for details. Apache Arrow is integrated with Spark since version 2.3.
conda install -c conda-forge pyarroworpip install pyarrow
Enable PyArrow — Its usage is not automatic and it will require some minor changes to configuration or code to take full advantage and ensure compatibility. To use Arrow when running PySpark application, users need to first set the Spark configuration ‘spark.sql.execution.arrow.enabled’ to ‘true’. This is disabled by default.
spark.conf.set(“spark.sql.execution.arrow.enabled”, “true”)
If you want to enable this for all of your spark sessions, add the below line to your Spark configuration at SPARK_HOME/conf/spark-defaults.conf.
spark.sql.execution.arrow.enabled=true
Let’s run code with Arrow enabled
# Now Enable Arrow-based columnar data transfers in Spark
spark.conf.set(“spark.sql.execution.arrow.enabled”, “true”)%time df2 = spark.createDataFrame(pdf2)

The above code takes a wall time of 57ms — which is much more reasonable than 3 seconds! The results are more convenient to use Arrow to decrease time conversion.
Now that all of the serialization and processing is out of the way, the time is now mostly due to IO. Here Arrow allows the NumPy data to be sent to the JVM in batches where it can be directly consumed without doing a bunch of conversions while still ensuring accurate type info.
How does the PyArrow enabled conversion work internally?
- Pandas DataFrame will be distributed to chunks as per the Spark default parallelism
- Then the each distributed chunk’s data is converted into Arrow’s
RecordBatch - Now Spark schema will be created from Arrow data which has all the type definitions. Currently, all Spark SQL data types are supported by Arrow-based conversion except
MapType,ArrayTypeofTimestampType, and nestedStructType² - Then
RecordBatches or Arrow Data will be transferred to JVM to create Java RDD - Finally, add the Spark Schema with JavaRDD to create a final
DataFrame
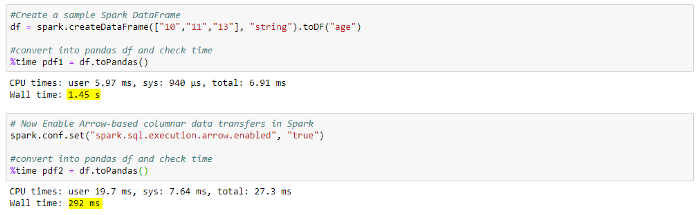
Lastly, PyArrow can also optimize the opposite scenario where we need to convert Spark DF to Pandas DF. See below screenshot from Jupyter Notebook.
Notes
- One more thing to consider while enabling Arrow is that the default batch size of Arrow data is limited to 10,000 Spark rows, which can be adjusted by setting the conf “spark.sql.execution.arrow.maxRecordsPerBatch” to any number. This configuration should be tweaked only if you know your memory limits as this will be used for creating a number of record batches for processing based on your each data partition
- Let’s suppose you have enabled the PyArrow. If while converting the data using PyArrow, an error occurs in Spark application, Spark will switch back to non-Arrow optimization automatically with the ‘spark.sql.execution.arrow.enabled’ configuration set to ‘false’ by default. Thus your application will not crash in the middle of execution due to PyArrow
The Takeaway
The blog was focused on how to implement Apache Arrow in Spark to optimize the conversion between pandas DataFrame and Spark DataFrame. We explored its internal implementation and even compared with and without enabling Apache Arrow scenarios. Now you can also switch between Arrow enabled or disabled and see the performances side by side.
Developers at IBM who originally worked on developing this “PySpark to incorporate Arrow” noted in one of the presentations that they achieved 53x speedup in data processing in PySpark after adding support for Arrow.
In the end, we would suggest you visit the official page to know more about the latest updates and improvements. Don’t forget to check out our Data Engineering solutions for all your business requirements.
References
Apache Arrow: A cross-language development platform for in-memory data
Python library for Apache Arrow
https://github.com/apache/arrow/tree/master/python
PySpark Usage Guide for Pandas with Apache Arrow
https://spark.apache.org/docs/latest/sql-pyspark-pandas-with-arrow.html