An introduction to AWS SageMaker — Machine Learning Classification Problem with Bank Marketing Data Set
Clairvoyant carries vast experience working with AWS and its many offerings. Amazon SageMaker is one such offering that helps Data Scientists, Machine Learning (ML) Engineers and Developers build end to end solutions for Machine Learning use cases.
Tapping into Clairvoyant’s expertise with AWS, this blog discusses Bank Marketing Dataset, a Classification Problem, where the goal is to predict if a client will subscribe to a term deposit with direct marketing campaigns.
What is Amazon SageMaker?
Amazon SageMaker, an Integrated Development Environment like solution offers true abstraction for the categories associated with ML problems:
- Build: Define the problem, gather, analyze, clean and preprocess raw data
- Train: Apply machine learning algorithms, train the model and apply hyperparameter tuning to gain better results
- Deploy: Deploy the model into a production environment, i.e. scale the solution
Amazon SageMaker does a fantastic job by providing a unified platform to work on all the above 3 segments of a Machine Learning Use Case.
How to use Amazon SageMaker Setup Setup?
To work with SageMaker, a basic idea of the other AWS components used by SageMaker is of importance. SageMaker uses the following:
- a Juptyer Notebook Interface for developers to write code
- an EC2 instance for computation tasks such as preprocessing, cleaning, etc.
- an Elastic Block Storage (EBS) which acts as the file system
- an ephemeral cluster for training the model
- Elastic Container Registry (ECR) from where the training algorithm is downloaded, and
- an S3 bucket to store the train, validation, test data sets and the model artifact after training
To start off, let’s get a SageMaker notebook instance set up. On the SageMaker console, you should see a tab called ‘notebook instances’. Click on ‘create notebook instance’ on the top right corner of the page, and it should route to the configuration page of the instance. Give any name for the notebook instance, and assign the instance with an IAM role. On default assignment, the IAM policy attached is AmazonSageMakerFullAccess policy.
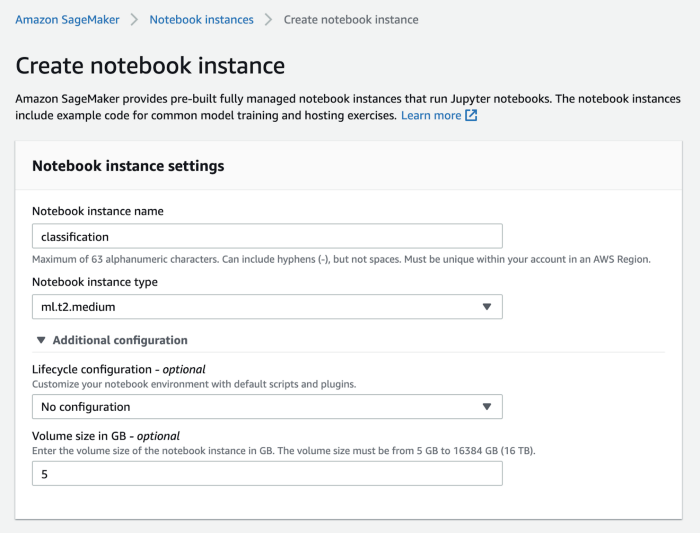
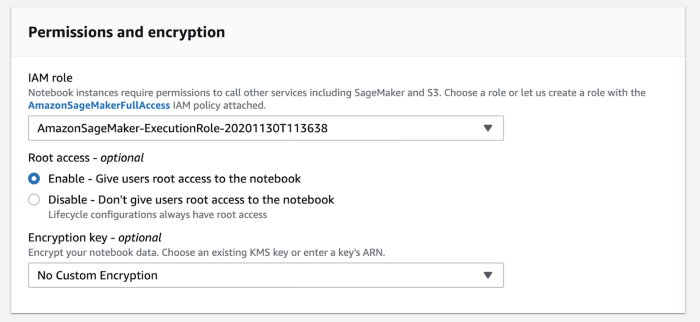
You can also modify the type of instance fitting the needs of the project and the volume size of the notebook using Amazon SageMaker. For this use case, 5 GB is sufficient. You can additionally attach a git repository to make use of any existing code. You can also assign a custom IAM role with restricted access. Once all parameters are fed in, go ahead, click on the ‘create notebook instance’ tab at the bottom. You should be able to see the new notebook instance created under the notebook instances tab.
To start a notebook instance, just click on ‘Start’ under ‘Action’ of that particular notebook instance. Once the status on the notebook turns from pending to InService, you should see the tab ‘Open Jupyter’ under actions:
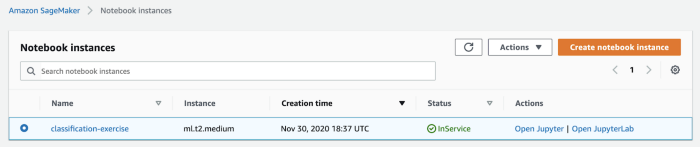
Click on ‘Open Jupyter’ and it should route you to the file system of the instance on the Jupyter IDE. To get an idea of what exists in the EBS file system of the notebook instance, under the ‘New tab’ on the top right corner, click on ‘Terminal’ from the drop-down menu. Type ls on the command prompt, and you should see the following contents:

The mount point for your notebook instance will be under the folder SageMaker — any files and folders for your project will be available under the folder SageMaker. Navigate back to the Jupyter Notebook IDE, on the top, you should see the ‘SageMaker Examples’ tab. Under this tab, there are a lot of example notebooks on how to use Amazon SageMaker for different Use Cases. Now going back to the ‘Files’ tab on the Jupyter Notebook, create a new folder for the classification task. Under this folder, we will now have our python program to implement the Classification problem.
SageMaker Components
First, import the SageMaker Python SDK. This package has all the components necessary to use the SageMaker functionality.

A few key items to understand here:
- import sagemaker : A python SDK
- sagemaker.Session() : A session variable with sagemaker resources available
- get_execution_role(): An IAM role associated with the sagemaker session
- default_bucket() : A default S3 bucket is created with the session if no bucket is specified
If a session is closed, or the notebook instance is stopped, the EBS (Elastic Block Storage) still persists.
Describe the Data
We will only briefly talk about the data and the preprocessing steps taken, as the main focus of this article is to understand SageMaker and how to use it. The data set is from the UCI Machine Learning repository, and we will be making use of the bank.csv data. The data has 1 target column — ‘y’ and 16 features, out of which 10 columns are categorical. The dataset is also highly imbalanced, with more outcomes indicating a client will not subscribe to a term deposit with bank marketing. The data also has no empty fields, it is completely populated.
The preprocessing steps involve cleaning up the categorical variables by combining similar categories together and expanding them into dummy variables. If the columns are binary categorical variables, they have been converted to the numeric form. Some columns have also been dropped as they have no intrinsic meaning. Many preprocessing methods are available on Kaggle for this dataset, and the version here can be used as a reference.
S3 data channel for Train Data
Once the data is preprocessed, it is ready to be split into train (80%) and test (20%) sets. To use the SageMaker provided training models, the data needs to be formatted a certain way. The target column has to be the first column in the dataframe and there should be no headers included in the CSV when uploading to S3.

Upload the test data in the same fashion as the above image.
Another thing to keep in mind is that the S3 bucket should be in the same region as your training job. Once the data is uploaded to S3, for the model to access the training data, you will need to create an S3 channel to provide a pathway for the data into the training algorithm. The training model will also need an output location for the model artifact to be stored after the training job is complete.

The inputs function configures a channel to the S3 data source. The parameters listed in the function are:
- s3_train_data: where the data resides on in s3. The full path of the variable is defined above.
- distribution: on choosing FullyReplicated, the entire train data is used on each ML compute instance when launched for model training.
- content_type: type of input data.
- s3_data_type: uses objects that match the prefix when training the model.
This need not be done for the test data, the train channel alone would be sufficient. Follow the same steps as the train channel if a validation set also needs to be added.
Training the Model
The training algorithms, i.e. the Estimators in SageMaker are pulled in as docker images. The image we need for binary classification would be the linear-learner which is a built-in SageMaker algorithm. If you would like to use your own training algorithm, upload your training algorithm in the form of a docker image in the Elastic Container Registry and provide an entrypoint to access the algorithm.

Now that the container which has the training algorithm is ready, it is now time to initialize the Estimator:

The parameters defined in the estimator function are:
- instance_count = 1: One new EC2 dedicated to training the model
- instance_type = “< >” : The new EC2 instance type
- container: can be script mode, docker container, AWS marketplace, SageMaker containers, etc. which contain the model which lives in the ECR
- role: the role associated with the notebook instance, with the attached policies
The estimator also has hyperparameters assigned to it where the number of features after preprocessing is 26, and the predictor_type is binary_classifier. Linear learner also has the regressor method as predictor_type which can be used for regression problems.
Now that the estimator is defined, all that needs to be done is fitting the model to the training data. This should kick off a training job which may take a few minutes. Once the training job is finished, you should see the model artifact stored in the output path defined before on S3.
Deploy Model for Predictions
After training the model, for the predictions to work, you will need to deploy the model on an endpoint.

Once the endpoint is created, the test data needs to be passed in a format the predictor understands. The input to the predictor is in a csv format and the output from the predictor is in a json format.

Now, download the test file from S3 and parse each row in the dataframe for predictions like so:

The final_df in the above code segment has the ground truth in the actual column and the predicted value by the model in the predicted column. The accuracy metric on the above predictions turns out to be 0.9010174740101747. There’s definitely scope for improvement, but a 90% accuracy is a fairly good start.
After completing the exercise, make sure to delete the endpoints created for predictions and also stop your notebook instances from running continuously.
Conclusion
With this article, we’ve learned how to leverage SageMaker to completely implement a Machine Learning exercise. SageMaker offers structure in terms of using compute resources for specific tasks which when managed properly can be cost-effective, a data store for large volumes of data with S3 buckets, logging and monitoring with CloudWatch, in-built hyperparameter tuning jobs with bayesian optimizer methods and so much more. Given all these services are from the AWS platform, the integration between them is seamless. SageMaker also offers tons of sample notebooks to make use of for different problems like text classification, image classification, etc.
Clairvoyant is an AI solutions provider that caters to all your business requirements, check out our services to know more!
References