Read more to learn how to deploy Kafka cluster on Ubuntu 18.04 using Virtual Box.
 Source: https://kafka.apache.org, https://design.ubuntu.com, and www.virtualbox.org
Source: https://kafka.apache.org, https://design.ubuntu.com, and www.virtualbox.org
Our previous blogs detailed the steps to install Ubuntu 18.04 LTS Server on VirtualBox and a tutorial that helped set up Ubuntu servers using Virtualbox 6 on a Windows 10 operating system.
What is Kafka?
Kafka is a distributed messaging system that provides fast, highly scalable, and redundant messaging through a public subscribe distributed messaging system. Kafka was developed by LinkedIn and open-sourced in 2011. Kafka is written in Scala.
Kafka is a “public subscribe distributed messaging system” rather than a “queue system” since the message is received from the producer and broadcasted to a group of consumers rather than a single consumer.
A remarkable feature of Kafka is that it is highly available, immune from node failures, and has automatic recovery. All the above makes Apache Kafka an ideal tool for communication and integration between different parts of a large-scale data system in real-world data systems.
Kafka was meant to operate in a cluster, and we should be creating a cluster if you’re using Kafka.
The architecture of Kafka:
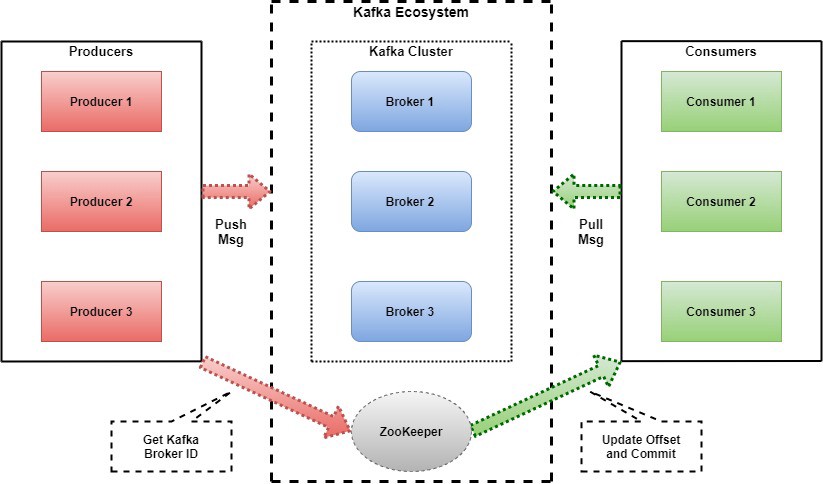 Kafka Architecture Diagram
Kafka Architecture Diagram
Topic:
Messages are published to a ‘Topic,’ and a partition is associated with each ‘Topic’. Kafka stores and organizes messages across its system, and essentially, a collection of messages are called Topics.
Brokers:
Broker in Kafka holds the messages that have been written by the producer before being consumed by the ‘consumer’.
Kafka cluster contains multiple brokers. A broker has a partition, and as already communicated, each partition is associated with a topic. The brokers receive the messages, and they are stored in the “brokers” for ’n’ number of days (which can be configured). After the ’n’ of days has expired, the messages are discarded. It is important to state here again that Kafka does not check whether each consumer or consumer group has read the messages.
Producer:
Different producers like Apps, DBMS, NoSQL write data to the Kafka cluster and publish messages to a Kafka topic.
Consumer:
A consumer or consumer group is/are subscribed to different topics, and in turn, they read from the partition for the topics to which they are subscribed. After the “producers” produced the message and sent it to the Kafka brokers, the consumers then read it. If a broker goes down, other brokers support the system and make sure everything runs smoothly.
ZooKeeper:
The Zookeeper’s primary responsibility is to coordinate with the different components of the Kafka cluster. The producer has the job to give the message to the broker leader/active controller, which in turn writes the message onto itself and replicates it to other brokers.
Zookeeper helps maintain consensus in the cluster, which means all the brokers know each other and know which one is the controller.
Requirements:
Please go through the installation of the Ubuntu server 18.04 LTS on Virtual Box as per the requirement for creating the multi-node Kafka cluster. Links:
Softwares:
1. VirtualBox
You can download the VirtualBox from the below link as per your operating system.
https://www.virtualbox.org/wiki/Downloads
2. Ubuntu 18.04 LTS ISO image.
Here is the link to download the image. https://releases.ubuntu.com/18.04.4/ubuntu-18.04.4-live-server-amd64.iso
3. Kafka packages 2.4.1
https://kafka.apache.org/downloads
Pre-requisites:
1. Install open JDK on VM’s
Use the following command to install the latest Java Developer Kit (JDK):
sudo apt install -y default-jdk
Use the following command to verify that Java has been installed:
java -version
2. Disable Swap usage on VM’s
Use the following command to disable RAM swap:
swapoff -a
Use the following command to comment out swap in the /etc/fstab file:
sudo sed -i '/ swap / s/^/#/' /etc/fstab
Now, lets set up the Kafka Cluster:
A. Download the Kafka Packages
Download the Kafka package:
wget https://www.apache.org/dyn/closer.cgi? path=/kafka/2.4.1/kafka_2.13-2.4.1.tgz
Extract the tar file and move it into the /tmp directory:
tar -xvf kafka_2.13-2.4.1.tgz sudo mv kafka_2.13-2.4.1 /tmp/kafka cd /tmp/kafka
B. Create a data directory to store Kafka messages and Zookeeper data.
Step- 1. Create a New Directory for Kafka and Zookeeper
sudo mkdir -p /kafka sudo mkdir -p /zookeeper
Step- 2. Change ownership of those directories now:
sudo chown -R ubuntu:ubuntu /kafka sudo chown -R ubuntu:ubuntu /zookeeper
C. Create a Zookeeper ID on each VM.
Create a file in /zookeeper first VM named "myid" with the ID as "1": echo "1" > /zookeeper/myid
Create a file in /zookeeper Second VM named "myid" with the ID as "2": echo "2" > /zookeeper/myid
Create a file in /zookeeper Third VM named "myid" with the ID as "3": echo "3" > /zookeeper/myid
D. Modify the Kafka and Zookeeper Configuration Files on all VM’s
Step- 1. Open the server.properties file:
cd /tmp/kafka vi config/server.properties
Step- 2. Update broker.id and advertised.listners into server.properties configuration as shown below:
Note: Add the below configuration on all VM’s. Run each command in the parallel console.
# change this for each broker broker.id=[broker_number] # change this to the hostname of each broker advertised.listeners=PLAINTEXT://[hostname]:9092 # The ability to delete topics delete.topic.enable=true # Where logs are stored log.dirs=/kafka # default number of partitions num.partitions=8 # default replica count based on the number of brokers default.replication.factor=3 # to protect yourself against broker failure min.insync.replicas=2 # logs will be deleted after how many hours log.retention.hours=168 # size of the log files log.segment.bytes=1073741824 # check to see if any data needs to be deleted log.retention.check.interval.ms=300000 # location of all zookeeper instances and kafka directory zookeeper.connect=zookeeper1:2181,zookeeper2:2181,zookeeper3:2181/kafka # timeout for connecting with zookeeper zookeeper.connection.timeout.ms=6000
Step- 3. open the zookeeper.properties file on all VM’s.
vi config/zookeeper.properties
Step- 4. Paste the following configuration into the zookeeper.properties :
# the directory where the snapshot is stored. dataDir=/zookeeper # the port at which the clients will connect clientPort=2181 # setting number of connections to unlimited maxClientCnxns=0 # keeps a heartbeat of zookeeper in milliseconds tickTime=2000 # time for initial synchronization initLimit=10 # how many ticks can pass before timeout syncLimit=5 # define servers ip and internal ports to zookeeper server.1=zookeeper1:2888:3888 server.2=zookeeper2:2888:3888 server.3=zookeeper3:2888:3888
E. Create the init.d scripts to start and stop for Kafka and Zookeeper service
Kafka:
Step- 1. Open file /etc/init.d/kafka on each VM on virtual box and paste in the following:
sudo vim /etc/init.d/kafka
#!/bin/bash #/etc/init.d/kafka KAFKA_PATH=/tmp/kafka/bin SERVICE_NAME=kafka
PATH=$PATH:$KAFKA_PATH
case "$1" in start) # Start daemon. pid=`ps ax | grep -i 'kafka.Kafka' | grep -v grep | awk '{print $1}'` if [ -n "$pid" ] then echo "Kafka is already running" else echo "Starting $SERVICE_NAME" $KAFKA_PATH/kafka-server-start.sh -daemon /tmp/kafka /config/server.properties fi ;; stop) echo "Shutting down $SERVICE_NAME" $KAFKA_PATH/kafka-server-stop.sh ;; restart) $0 stop sleep 2 $0 start ;; status) pid=`ps ax | grep -i 'kafka.Kafka' | grep -v grep | awk '{print $1}'` if [ -n "$pid" ] then echo "Kafka is Running as PID: $pid" else echo "Kafka is not Running" fi ;; *) echo "Usage: $0 {start|stop|restart|status}" exit 1 esac
exit 0
Save and close the file.
Step- 2. Make the file /etc/init.d/kafka executable. Also, change the ownership and start the service:
sudo chmod +x /etc/init.d/kafka sudo chown root:root /etc/init.d/kafka sudo update-rc.d kafka defaults sudo service kafka start sudo service kafka status
Zookeeper :
Step- 1. Open file /etc/init.d/zookeeper on all VM’s on virtual box and paste in the following:
sudo vim /etc/init.d/zookeeper #!/bin/bash #/etc/init.d/zookeeper KAFKA_PATH=/tmp/kafka/bin SERVICE_NAME=zookeeper
PATH=$PATH:$KAFKA_PATH
case "$1" in start) # Start daemon. pid=`ps ax | grep -i 'org.apache.zookeeper' | grep -v grep |
awk '{print $1}'` if [ -n "$pid" ] then echo "Zookeeper is already running"; else echo "Starting $SERVICE_NAME"; $KAFKA_PATH/zookeeper-server-start.sh -daemon
/tmp/kafka/config/zookeeper.properties fi ;; stop) echo "Shutting down $SERVICE_NAME"; $KAFKA_PATH/zookeeper-server-stop.sh ;; restart) $0 stop sleep 2 $0 start ;; status) pid=`ps ax | grep -i 'org.apache.zookeeper' | grep -v grep |
awk '{print $1}'` if [ -n "$pid" ] then echo "Zookeeper is Running as PID: $pid" else echo "Zookeeper is not Running" fi ;; *) echo "Usage: $0 {start|stop|restart|status}" exit 1 esac
exit 0
Save and close the file.
Step- 2. Make the file /etc/init.d/zookeeper executable. Also, change the ownership and start the service:
sudo chmod +x /etc/init.d/zookeeper sudo chown root:root /etc/init.d/zookeeper sudo update-rc.d zookeeper defaults sudo service zookeeper start sudo service zookeeper status
F. Create a Topic
Create a topic named test:
./bin/kafka-topics.sh --zookeeper zookeeper1:2181/kafka --create --topic test --replication-factor 1 --partitions 3
Describe the topic:
./bin/kafka-topics.sh --zookeeper zookeeper1:2181/kafka --topic test --describe
For the best data engineering solutions for your business, reach out to us at Clairvoyant.