Kafka is a highly scalable, highly available queuing system, which is built to handle huge message throughput at lightning-fast speeds. Clairvoyant team has used Kafka as a core part of architecture in a production environment and overall, we were quite satisfied with the results, but there are still a few caveats to bear in mind.
The backdrop: For one of the largest health insurance companies in America, we had to build an archival system to house electronic copies of all documents produced for their members, and provide on demand search and retrieval of those documents based metadata and text content.
The solution: We built a system where events (which correspond to new documents produced) move through various queues. So, that the system can process them without getting overwhelmed and is scalable to handle huge number of documents that gets produced daily for all their members. Our messaging system of choice was…drum roll please…Kafka!
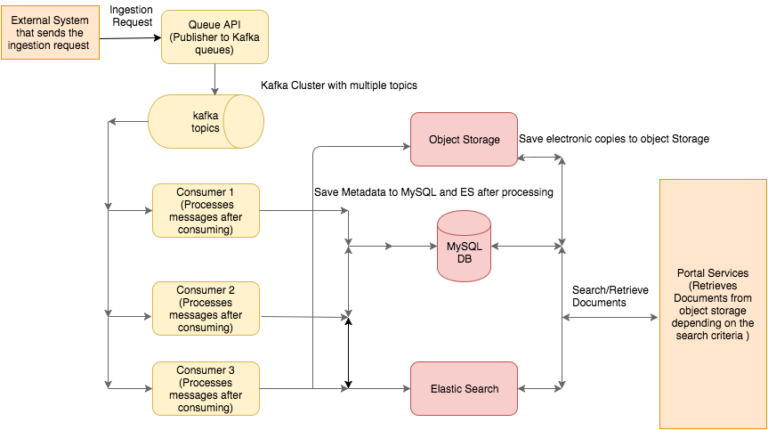
The diagram below gives a high level overview of the architecture. An external system makes a Rest call to the Queue API with the File Information and its metadata. The Queue API acts as a publisher and publishes the metadata to different Kafka topics. The consumers for these topics process the messages further and save the File (electronic copy) and metadata to object storage and MySQL/ES respectively.
The good: Kafka is designed as a distributed system, and it is fast, scalable, partitioned and replicated. It can handle messages at insane scale. http://thenewstack.io/streaming-data-at-linkedin-apache-kafka-reaches-1-1-trillion-messages-per-day/ ‘Nuff said. And it’s open source. And it’s fairly easy to get up and running in a production environment. And the documentation is great. It is built around the concepts of consumer groups and replicated topics, which make the system highly available and provide easy horizontal scalability.
The bad: Kafka is a little weak operationally. Which is to say that it doesn’t have robust native mechanisms for things like message monitoring. Though a lot of new open sourced monitoring tools are coming up as Kafka is becoming popular; we’ll talk about these later. Kafka is a commit log and it is expected that it is job of the consumer to handle the failed messages by putting the messages in a dead letter queue or publishing the messages back to the queue for retrying.
The meat: There’s nothing we can say here about the internals of Kafka which isn’t already explained clearly in its excellent documentation (http://kafka.apache.org/documentation.html). What’s typically more interesting is someone’s experience of deploying a technology into a production environment and gotchas that were encountered along the way.
Hardware and scale
We were running a 3-node cluster where each server had 4 x 2.7GHz cores, 16 GB of memory and 1 TB of hard disk space. Kafka persist messages on disk, so hard disk space is crucial.The number of messages we processed was on the order of about 3 million per day (yup…pretty low compared to the big boys). Pretty much all of this volume was funneled through 3 topics (a million a piece).
The Zookeeper/Kafka broker config
Each node was running an instance of Zookeeper (3.4.6) and Kafka (started with 0.8.2.1 and later updated to 0.10.0.0). Here’s how we set it up.
Zookeeper Setup
Version 3.4.6: http://apache.org/dist/zookeeper/zookeeper-3.4.6/
Unpack it: tar xvf zookeeper-3.4.6.tar.gz
Kafka setup
Version kafka_2.10–0.10.0.0: http://download.nextag.com/apache/kafka/0.10.1.0/kafka_2.11-0.10.1.0.tgz
Unpack it: tar xvf kafka_2.10–0.10.0.0.tgz
Topics and partitions
We had about 15 queues, each with 6 partitions and a replication factor of 2. Here is an example of how to create such a topic:
bin/kafka-topics.sh — create — zookeeper localhost:2181 — replication-factor 2 — partitions 6 — topic new.topic
Based on our fault-tolerance needs, we decided that each topic would be replicated once (this is specified as a replication factor of 2, which means 1 master and 1 replica). The number of partitions is important as this decides the max number of active consumers in a consumer group and the max capacity of parallel consumption you will be able to have for a particular topic.
Producers and consumers
Our Java application was built using micro-services architecture. Out of a total of 11 micro-services, 9 produced events, and 5 of the services were consumers. We started out using Kafka 0.8.2.1 with the Java producer and high-level consumer with spring integration. We subsequently upgraded to Kafka 0.10.0.0, in which a unified consumer was released (the high-level and simple consumer were merged into a unified consumer).
Java producer
Below are the Kafka producer configs we used:
Java consumer
A lot of properties need to be configured for the Kafka consumer. Before deciding their values, it is advisable to review the Kafka documentation on each property. A note on how Kafka handles consumers: It uses the concept of "consumer groups". A consumer group consists of multiple consumers amongst which messages are distributed. For example, say you have a topic with 6 partitions, and 3 consumers all consuming messages from that topic. Each consumer will get assigned 2 partitions to consume from, and messages are distributed accordingly. This gives Kafka the power of parallel consumption and fault tolerance (as partitions can be replicated across consumers). Also, another option is to set up multiple consumer groups which are subscribed to the same topic, in which case all messages are sent to both groups.
Below is how we configured the consumers:
Spring Integration
A special note here: Initially, we didn’t use the Java Kafka APIs as is; we used the Spring-Kafka adapter. This integration had pros and cons; on balance, we found it to be less intuitive and less flexible than using the Kafka APIs directly. On the upside, it provides a simple xml structure to configure a number of the consumer/producer properties. On the flip-side, however, it doesn’t support all features that the actual Kafka API provides. So we later moved to the Kafka APIs for consumers and producers.
Monitoring
There are some good open-source Kafka console monitors that are available; to name a few:
Developed by Yahoo: https://github.com/yahoo/kafka-manager
Developed by Linkedin: https://github.com/linkedin/kafka-monitor
However, we had a few specific requirements. We wanted to be able to send emails when a node is down, and we also wanted to run a job that constantly checks queue lag (the number of messages remaining to be consumed). If messages were being processed at a suboptimal rate, we wanted an email notification for that too. We had to build our own tool for this, and it ended being very helpful in understanding the status of the consumers in production. These are the APIs we used to get the information we needed:
-
admin.TopicCommand.listTopics : to list all the topics
-
admin.TopicCommand.describeTopic : gives us information about partitions in a topic and their corresponding leaders and followers
-
admin.ConsumerGroupCommand.main : gives us information about a particular consumer, the offset that is committed, and the lag
The verdict
Kafka is a great choice for handling messages at huge scale. Obviously it is; if it's the choice for a host of companies, and if it's only gaining a wider and wider foothold, it must be doing things right. We saw the strengths of this system play out in real-time (even though we did wrestle with one or two issues along the way). Kafka should be considered an essential part of any company's technology toolkit.
Learn how to write custom partitioner for Apache Kafka in our blog here. To get the best data engineering solutions for your business, reach out to us at Clairvoyant.