Apache Kudu is an open-source columnar storage engine. It promises low latency random access and efficient execution of analytical queries. The kudu storage engine supports access via Cloudera Impala, Spark as well as Java, C++, and Python APIs.
The idea behind this article was to document my experience in exploring Apache Kudu, understanding its limitations, if any, and running some experiments to compare the performance of Apache Kudu storage against HDFS storage.
Installing Apache Kudu using Cloudera Manager
Below is a link to the Cloudera Manager Apache Kudu documentation and can be used to install Apache Service on a cluster managed by Cloudera Manager.
https://docs.cloudera.com/documentation/enterprise/latest/topics/kudu.html
Accessing Apache Kudu via Impala
It is possible to use Impala to CREATE, UPDATE, DELETE and INSERT into kudu stored tables. Good documentation can be found here https://www.cloudera.com/documentation/kudu/5-10- x/topics/kudu_impala.html.
Creating a new table:
CREATE TABLE new_kudu_table(id BIGINT, name STRING, PRIMARY KEY(id))
PARTITION BY HASH PARTITIONS 16 STORED AS KUDU;
Performing insert, updates, and deletes on the data:
--insert into that table INSERT INTO new_kudu_table VALUES(1, "Mary"); INSERT INTO new_kudu_table VALUES(2, "Tim"); INSERT INTO new_kudu_table VALUES(3, "Tyna");
--Upsert when the insert is meant to override existing row UPSERT INTO new_kudu_table VALUES (3, "Tina");
--Update a Row UPDATE new_kudu_table SET name="Tina" where id = 3;
--Update in Bulk UPDATE new_kudu_table SET name="Tina" where id<3;
--Delete DELETE FROM new_kudu_table WHERE id = 3;
It is also possible to create a kudu table from existing Hive tables using CREATE TABLE DDL. In the below example script if table movies already exist then Kudu backed table can be created as follows:
CREATE TABLE movies_kudu PRIMARY KEY (`movieid`) PARTITION BY HASH(`movieid`) PARTITIONS 8 STORED AS KUDU AS SELECT movie, title, genres FROM movies;
Limitations when creating a Kudu table:
Unsupported data-types: When creating a table from an existing hive table, if the table has VARCHAR(), DECIMAL(), DATE, and complex data types(MAP, ARRAY, STRUCT, UNION), then these are not supported in Kudu. Any attempt to select these columns and create a kudu table will result in an error. If a Kudu table is created using SELECT *, then the incompatible non-primary key columns will be dropped in the final table.
Primary Key: Primary keys must be specified first in the table schema. When creating a Kudu table from another existing table where primary key columns are not first — reorder the columns in the select statement in the make table statement. Also, Primary key columns cannot be null.
Access Kudu via Spark
Adding kudu_spark to your spark project allows you to create a kuduContext which can be used to develop Kudu tables and load data to them. Note that this only makes the table within Kudu and, if you want to query this via Impala you would have to create an external table referencing this Kudu table by name.
Below is a simple walkthrough of Kudu spark to create tables in Kudu via spark. Let's start with adding the dependencies,
<properties>
<jdk.version>1.7</jdk.version>
<spark.version>1.6.0</spark.version>
<scala.version>2.10.5</scala.version>
<kudu.version>1.4.0</kudu.version>
</properties>
<dependency>
<groupId>org.apache.kudu</groupId>
<artifactId>kudu-spark_2.10</artifactId>
<version>${kudu.version}</version>
</dependency>
Next, create a KuduContext as shown below. As the library for SparkKudu is written in Scala, we would have to apply appropriate conversions, such as converting JavaSparkContext to a Scala compatible
import org.apache.kudu.spark.kudu.KuduContext;
JavaSparkContext sc = new JavaSparkContext(new SparkConf());
KuduContext kc = new KuduContext("<master_url>:7051",
JavaSparkContext.toSparkContext(sc));
If we have a data frame that we wish to store to Kudu, we can do so as follows:
import org.apache.kudu.client.CreateTableOptions; df = … // data frame to load to kudu primary key list = .. //Java List of table's primary keys
CreateTableOptions kuduTableOptions = new CreateTableOptions(); kuduTableOptions.addHashPartitions( <primaryKeyList>,<numBuckets>);
// create a scala Seq of table's primary keys Seq<String> primary_key_seq = JavaConversions. asScalaBuffer(primaryKeyList).toSeq();
//create a table with same schema as data frame kc.createTable(<kuduTableName>, df.schema(),primary_key_seq,
kuduTableOptions);
//load dataframe to kudu table kc.insertRows(df, <tableName>);
Limitations when using Kudu via Spark:
Unsupported Datatypes: Some complex datatypes are unsupported by Kudu and creating tables using them would through exceptions when loading via Spark. Spark does manage to convert the VARCHAR() to a spring type, however, the other classes (ARRAY, DATE, MAP, UNION, and DECIMAL) would not work.
We need to create an External Table if we want to access it via Impala: The table made in Kudu using the above example resides in Kudu storage only and is not reflected as an Impala table. To query the table via Impala we must create an external table pointing to the Kudu table.
CREATE EXTERNAL TABLE IF NOT EXISTS <impala_table_name>
STORED AS KUDU TBLPROPERTIES('kudu.table_name'='<kudu_table_name>');
Apache Kudu and HDFS Performance Comparison
The objective of the Experiment
The idea behind this experiment was to compare Apache Kudu and HDFS in terms of loading data and running complex Analytical queries.
Experiment Setup
-
Dataset Used: The TPC Benchmark™H (TPC-H) is a decision support benchmark, emulating typical business datasets and a suite of complex analytical queries. One can find a good source to generate this dataset and load it to the hive at https://github.com/hortonworks/hive-testbench. The dataset has eight tables and can be generated at different scales from 2 Gb onwards. For this test, 20Gb of total data is generated.
-
Cluster Setup: The cluster has 4 Amazon EC2 instances with one master(m4.xlarge) and 3 data nodes(m4.large). Each cluster has 1 disk of size 150 Gb. The cluster is managed via Cloudera Manager.
Data Loads Performance:
Table 1. shows the time in secs between loading to Kudu vs. Hdfs using Apache Spark. The Kudu tables are hash partitioned using the primary key.
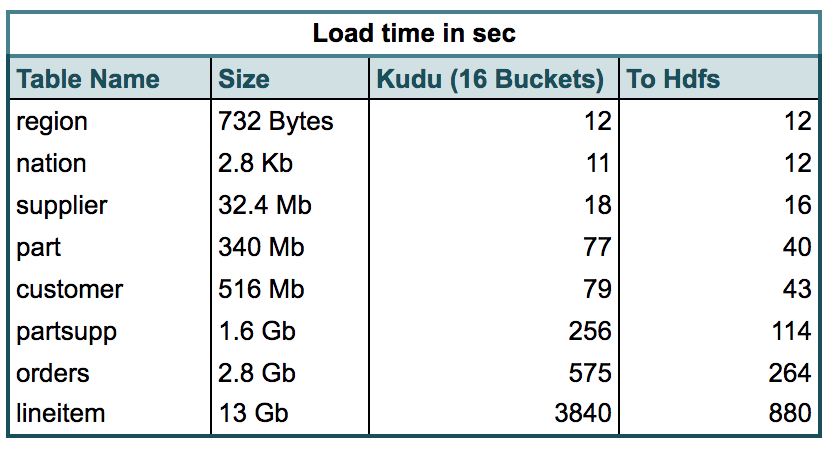 Table 1. Load times for the tables in the benchmark dataset
Table 1. Load times for the tables in the benchmark dataset
Observations: From the table above we can see that Small Kudu Tables get loaded almost as fast as Hdfs tables. However, as the size increases, we do see the load times becoming double that of Hdfs with the largest table line-item taking up to 4 times the load time.
Analytical Queries performance:
The TPC-H Suite includes some benchmark analytical queries. The queries were run using Impala against HDFS Parquet stored table, Hdfs comma-separated storage, and Kudu (16 and 32 Buckets Hash Partitions on Primary Key). The runtime for each query was recorded, and the charts below show a comparison of these run times in sec.
Comparing Kudu with HDFS Parquet:
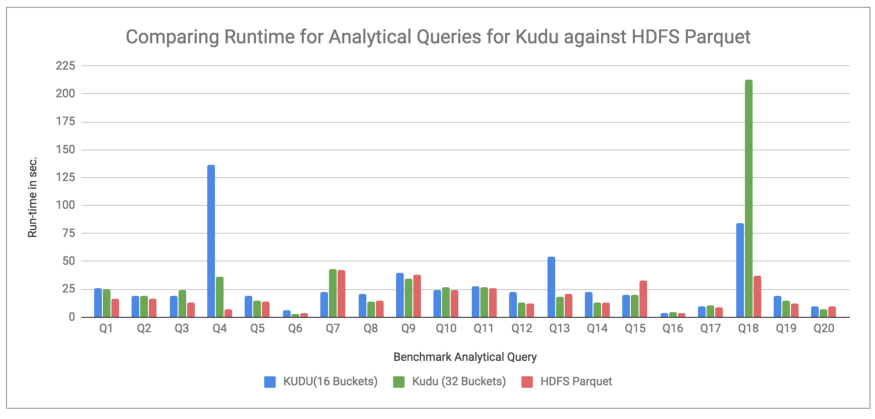 Chart 1. Running Analytical Queries on Kudu and HDFS Parquet
Chart 1. Running Analytical Queries on Kudu and HDFS Parquet
Observations: Chart 1 compares the runtimes for running benchmark queries on Kudu and HDFS Parquet stored tables. We can see that the Kudu stored tables perform almost as well as the HDFS Parquet reserved tables, except for some queries(Q4, Q13, Q18), where they take a much longer time than the latter.
Comparing Kudu with HDFS Comma Separated storage file:
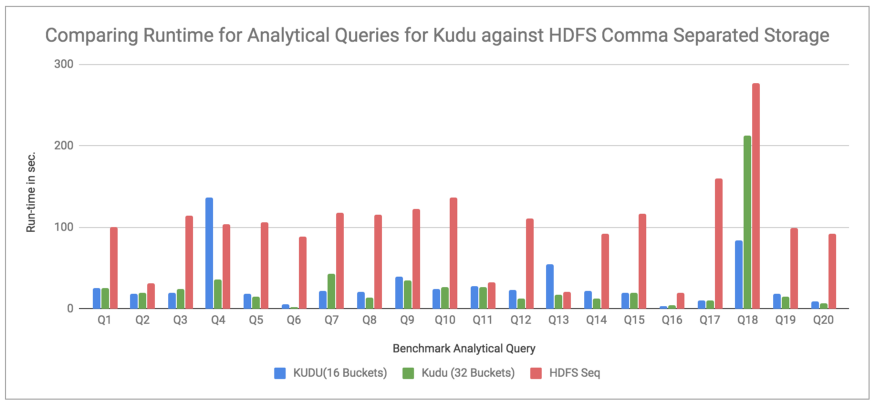 Chart 2. Running Analytical Queries on Kudu and HDFS Comma Separated file
Chart 2. Running Analytical Queries on Kudu and HDFS Comma Separated file
Observations: Chart 2 compared the kudu runtimes (same as chart 1) against HDFS Comma separated storage. Here we can see that the queries take a much longer time to run on HDFS Comma separated storage than Kudu, with Kudu (16 bucket storage) having runtimes on an average 5 times faster and Kudu (32 bucket storage) performing 7 times better on an average.
Random Access Performance:
Kudu boasts of having much lower latency when randomly accessing a single row. To test this, I used the customer table of the same TPC-H benchmark and ran 1000 Random accesses by Id in a loop. The runtimes for these were measured for Kudu 4, 16, and 32 buckets partitioned data and for HDFS Parquet stored Data. The chart below shows the runtime in sec. for 1000 Random accesses proving that Kudu indeed is the winner when it comes to random access selections.
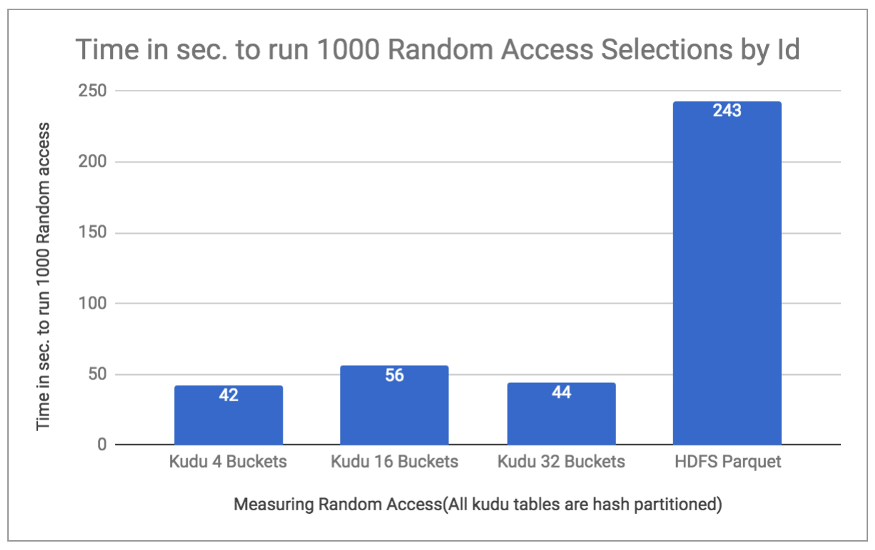 Chart 3. Comparing time for Random Selections
Chart 3. Comparing time for Random Selections
Kudu Update, Insert and Delete Performance
Since Kudu supports these additional operations, this section compares the runtimes for these. The test was setup similar to the random access above with 1000 operations run in loop and runtimes measured which can be seen in Table 2 below:
 Table 2. Measuring Runtime for Various Operations
Table 2. Measuring Runtime for Various Operations
Conclusion
Just laying down my thoughts about Apache Kudu based on my exploration and experiments.
As far as accessibility is concerned I feel there are quite some options. It can be accessed via Impala which allows for creating kudu tables and running queries against them. SparkKudu can be used in Scala or Java to load data to Kudu or read data as Data Frame from Kudu. Additionally, Kudu client APIs are available in Java, Python, and C++ (not covered as part of this blog).
There are some limitations with regards to datatypes supported by Kudu and if a use case requires the use of complex types for columns such as Array, Map, etc. then Kudu would not be a good option for that.
The experiments in this blog were tests to gauge how Kudu measures up against HDFS in terms of performance.
From the tests, I can see that although it does take longer to initially load data into Kudu as compared to HDFS, it does give a near equal performance when it comes to running analytical queries and better performance for random access to data.
Overall I can conclude that if the requirement is for storage which performs as well as HDFS for analytical queries with the additional flexibility of faster random access and RDBMS features such as Updates/Deletes/Inserts, then Kudu could be considered as a potential shortlist.
Also, check out or blog "Installing Apache Kudu on Cloudera’s Quickstart VM" here. To get the best data engineering solutions for your business, reach out to us at Clairvoyant.