An Introduction to NLP and its usage in end-to-end implementation of a classification model.
At Clairvoyant, we have the expertise of working with Natural Language Processing (NLP)-, Machine Learning (ML)-, and related data solutions. With the help of a model that we’ve designed, we can categorize the data that carries the required information for analysis purposes. In this blog, we will go through one of the classification models where we classify the disaster-related tweets from the rest.
We are trying to categorize Twitter data that is related to natural disasters in this blog, and the dataset can be obtained from here.
Twitter is a very common forum for social media that enables us to:
-
Reach a significant number of individuals and new audiences
-
Build relationships with experts
-
Keep ourselves up-to-date with the latest news and trends
Every industry and government relies on social media sites for public opinions and views in the new digital world.
For any company, once a product is launched in the market, the management needs to consider its customers’ points of view and the various difficulties faced by them. But does all the data collected from these platforms carry the information that we are looking for?
Instead of analyzing the entire dataset, we need to sort out or classify the required information data. Our model consists of Natural Language Processing (NLP) and a classification algorithm to facilitate this process.
Natural Language Processing (NLP):
Twitter is a blogging system that allows you to express your views on any topic. To make models understand and derive meaning from these human languages, we use NLP. This interaction between computers and humans developed by the NLP has various applications such as Sentimental Analysis, Topic extraction, and many more.
Once the model understands and extracts meaning from these tweets, we use a classification algorithm that helps better classify each tweet's significance.
Classification Algorithm:
Classification is a classic example of a Supervised Machine Learning algorithm. We use a pre-categorized training dataset to train the model so that it is capable of categorizing any of the new data provided to it.
The various types of classification algorithms include:
Logistic Regression
Naive Bayes Classifier
K-Nearest Neighbors
Decision Tree
Random Forest
Support Vector Machines
That concludes the theory part, so let’s start with the coding section.
Initially, we will import all the basic packages and then import the respective data.
Here is a quick view of the raw training data:
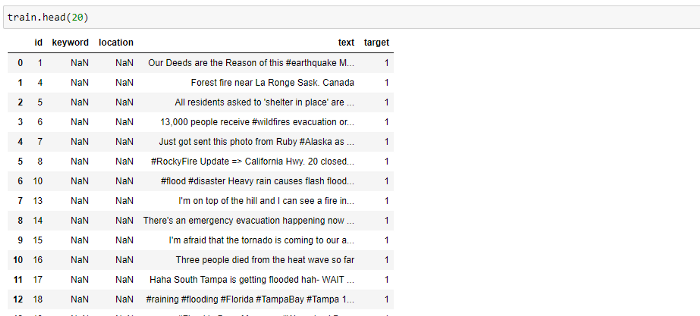
We then check the shape of both the training and test dataset along with the number of Disastrous and Non-Disastrous tweets present in the training dataset where we use the histogram plot.

We now check the data for any Null values and the respective data format for each column.
As this is a Twitter dataset, we also need to consider removing special characters and punctuations from it.

We also use WordCloud here to see the most repetitive words in the whole dataset.
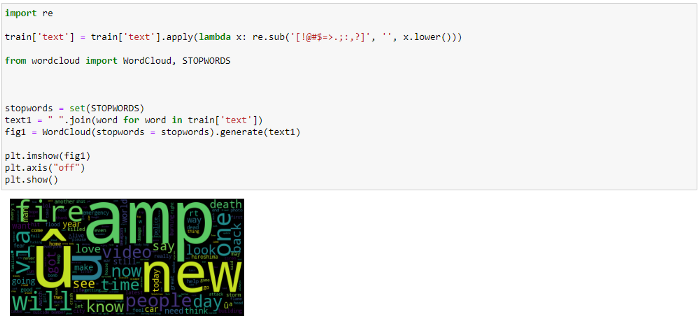
The same operation is performed on the test dataset as well.
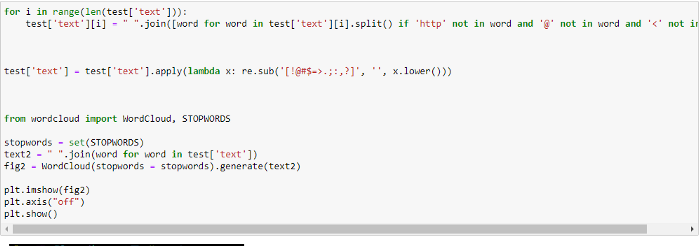
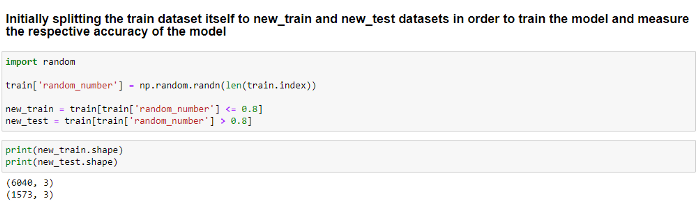
Since we use a Supervised Learning Methodology, we need both training data to train the model and test data to validate the model’s accuracy. For this reason, with an 80:20 ratio, we split the given train dataset into new_train and new_test datasets.
To make the model understand and analyze the Twitter data, we Tokenize these datasets. Tokenization is the process of splitting the entire text or sentences into tokens, also known as words. For this purpose, we use the Countvectorizer.
Countvectorizer, provided by the sci-kit-learn library, is a great tool to convert a text into a vector-based on its frequency. It creates a matrix where each word is represented as a column.
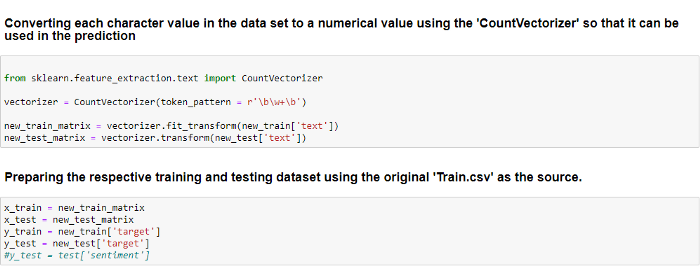
Using this tool, we generate two new inputs, ‘new_train_matrix’ and ‘new_test_matrix’, which are later used for Machine Learning models as x_train and x_test. ‘new_train[‘target’]’ and ‘new_test[‘target’]’ are considered as y_train and y_test, respectively.
We begin by considering the classification algorithm kNN (k Nearest Neighbors), one of the significant classification models. To classify any new data input, this model uses its nearest neighbors. The input parameter ‘k’ here reflects the number of neighbor data points that need to be taken into account for classification.
Here, we are importing KNeighborsClassifier from the sklearn library. Later, we are preparing the model by considering k=7. We train the model using x_train and y_train.
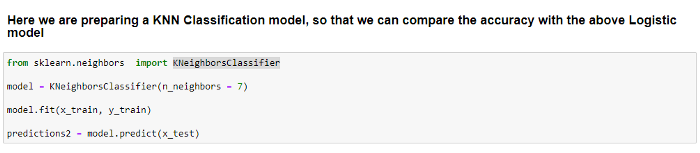
Once trained, we use the model to predict all the values in x_test.
The accuracy of the model is determined using the ‘confusion matrix’ and ‘classification report’.
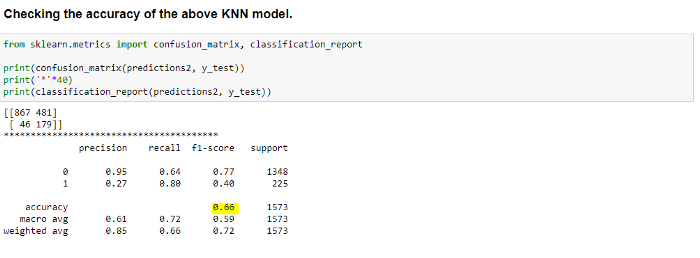
As we can see above, we are getting only 66 percent accuracy using this model, which is quite low.
Clearly, we have to consider a different model that offers more accuracy for this dataset.
We now consider the Logistic Regression model, another popular algorithm used for classification.
Logistic Regression is almost equivalent to Linear Regression. The major difference between the two models is that, rather than integer values, the output of the logistic model is binary values.

Here, we import the LogisticRegression from the same sklearn library and use the same x_train and y_train data to train the model. We use lr.predict(x_test) to predict the data for x_test.
Hope you liked it! This article gave a brief idea of how tweets can be classified. We used the NLP process for cleaning and preparing the data, followed by classification models. Based on the dataset, we can use different classification models (as stated above) and compare the performance of each model.Here, we get 80 percent accuracy, which is very good when compared to the kNN model.
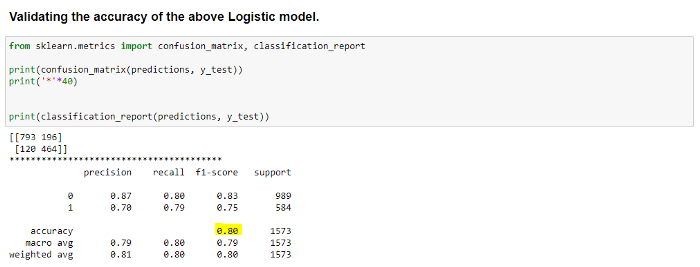
Hence, we are moving forward with this model.
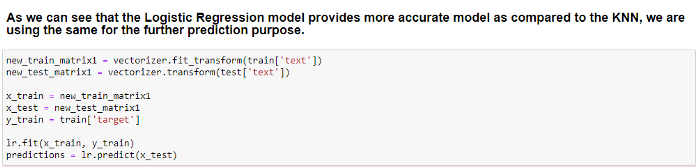
With the help of CountVectorizer, we are using the same concept of Tokenization here to convert the original train[‘text ‘] and test[‘text’] data to allow the model to understand and analyze them.
This new data is provided as input to the Logistic Regression model, and once trained, predictions are made for the test dataset.

We change the format and concatenate the predicted and test data to obtain the final data frame.
We can see from the above result that the model classifies all the disaster-related tweets as ‘1’ and the others as ‘0’.
Conclusion:
Hope you liked it! This article gave a brief idea of how tweets can be classified. We used the NLP process for cleaning and preparing the data, followed by classification models. Based on the dataset, we can use different classification models (as stated above) and compare the performance of each model.
To learn about compression techniques for convolutional neural networks, check out our blog here. To get the best artificial intelligence solutions for your business, reach out to us at Clairvoyant.
References:
https://algorithmia.com/blog/introduction-natural-language-processing-nlp
https://analyticsindiamag.com/7-types-classification-algorithms/