The journey from raw data to meaningful data
Our first blog on Building Data Lake on AWS explained the process of architecting a data lake and building a process for data ingestion in it.
Clairvoyant has years of experience handling data processing challenges. Through this blog, we wish to document a few such challenges and our approach towards solving them on AWS. Read on to know how data can be processed efficiently.
Data Processing
Processing data to arrange it by type and information can save a lot of space taken up by unorganized and inconsistent data. Processed data can also help ensure that everyone understands it easily as it becomes readable. It becomes more useful, and when not processed, data can take up more time and end up generating a decreased output. Unorganized and inconsistent data can harm the interests of the business or organization.
Businesses require data to provide a good quality of service. Collecting data and its implications is a very important aspect of managing it and ensuring statistical authenticity. It is particularly essential for financial institutions where the transaction data and payment details need to be properly stored for easy access by customers and employees as and when needed.
Also, the data ingested in a data lake comes with different challenges. Some of them are:
-
High-value data like User information
-
High-scale time-series data
-
Duplicates
-
Small Files
-
Big Files
-
Consistency
Data Processing also helps overcome these data-related challenges.
Pillars of Data processing: Cleaning and Transformation
Data cleaning is the process that removes the data that does not belong in your dataset. Data transformation is the process of converting data from one format or structure into another.
Transformation processes can also be referred to as mapping data from one “raw” data form into a meaningful format for storage and analysis.
Before starting to Clean and Transform the data,
-
It’s better to define the business case
-
Data source investigation
-
Data profiling
and understand the difference.
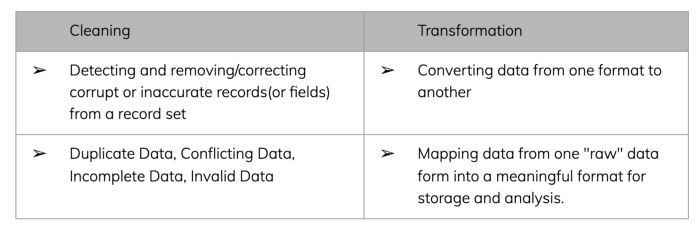 Diff. between Cleaning and Transformation
Diff. between Cleaning and Transformation
Benefits of data processing
Cleaning
-
Increases overall productivity
-
Protects applications from potential landmines, such as null values and unexpected duplicates
-
Gives the ability to map the different functions and what your data is intended to do
-
Figures out where errors are coming from, making it easier to fix incorrect or corrupt data for future applications
Transformation
-
Improves data organization
-
Protects applications from potential landmines such as incorrect indexing and incompatible formats
-
Facilitates compatibility between applications, systems, and types of data
-
Provides valuable information for your decision making
Steps involved in Data Processing
Transformation
-
Data interpretation
-
Data translation
-
Data profiling and quality checks
Cleaning
-
Data profiling
-
Remove duplicate or irrelevant observations
-
Fix structural errors
-
Filter unwanted outliers
-
Handle missing data
-
Validate and QA
Challenges while performing Data Processing
-
Resource intensive
-
Semantic Complexity
-
Multi-Source Problems
-
Single Source Problems
-
Need for subject matter expertise
-
Transformation and cleaning that doesn’t suit business needs
Comparison of tools used for Data Processing
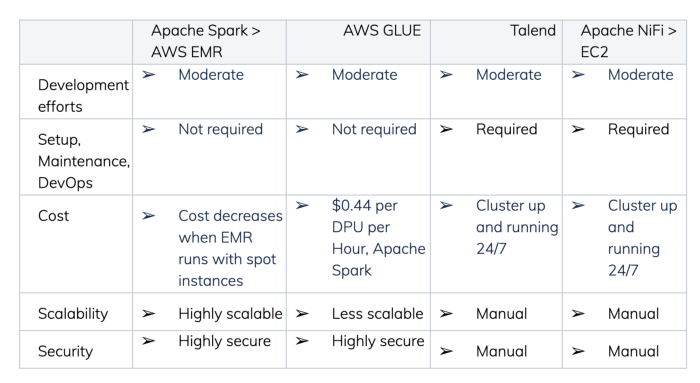 Diff. between Apache Spark Vs. AWS Glue Vs. Talend Vs. Apache Nifi
Diff. between Apache Spark Vs. AWS Glue Vs. Talend Vs. Apache Nifi
Key takeaways
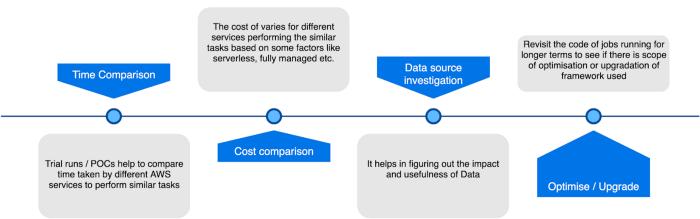 Key takeaways
Key takeaways