Spark job optimization using Bucketing
Clairvoyant utilizes the bucketing technique to improve the spark job performance, no matter how small or big the job is. It helps our clients lower the cost of the cluster while running jobs. Tapping into Clairvoyant’s expertise in bucketing, this blog discusses how the technique can help to enhance the Spark job performance.
What is bucketing?
Bucketing is a technique in both Spark and Hive used to optimize the performance of the task. In bucketing buckets (clustering columns) determine data partitioning and prevent data shuffle. Based on the value of one or more bucketing columns, the data is allocated to a predefined number of buckets.
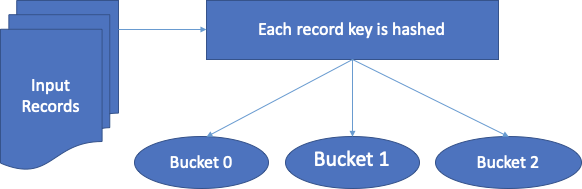 Figure 1.1
Figure 1.1
When we start using a bucket, we first need to specify the number of the buckets for the bucketing column (column name). At the time of loading, the data processing engine will calculate the hash value for that column, based on which it will reside in one of the buckets. Although not mandatory, using a partitioned table to do the bucketing will give the best results.
Bucketing has two key benefits:
-
Improved query performance: At the time of joins, we can specify the number of buckets explicitly on the same bucketed columns. Since each bucket contains an equal size of data, map-side joins perform better than a non-bucketed table on a bucketed table. In a map-side join, the left-hand side table bucket will exactly know the dataset contained by the right-hand side bucket to perform a table join in a well-structured format.
-
Improved sampling: The data is already split up into smaller chunks so sampling is improved.
Bucketing involves sorting and shuffling the data prior to the operation which needs to be performed on data like joins.
Bucketing boosts performance by sorting and shuffling data before performing downstream operations, such as table joins. This technique benefits dimension tables, which are frequently used tables containing primary keys. It’s also beneficial when there are frequent join operations requiring large and small tables.
Bucketing is commonly used to optimize the performance of a join query by avoiding shuffles of tables participating in the join. It is beneficial to bucketing when pre-shuffled bucketed tables are used once within the query.
When we enable the buckets, it is critical that we specify the bucket number, for this, one needs to have an insight into the data. Alternatively, we can perform a hit and try to get the best number of buckets. Alternatively, we can start with the number that is the same as the number of the executor we have in our cluster and then adjust it till we get the best performance.
Spark DAG stages analysis
Without Bucketing:- We will create two datasets without bucketing and perform join, groupBy, and distinct transformation.
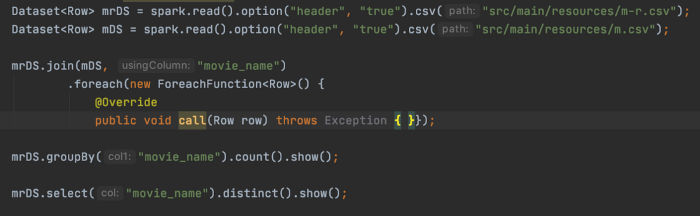
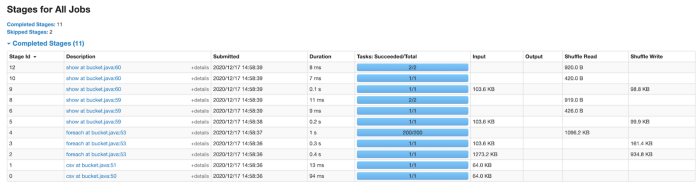
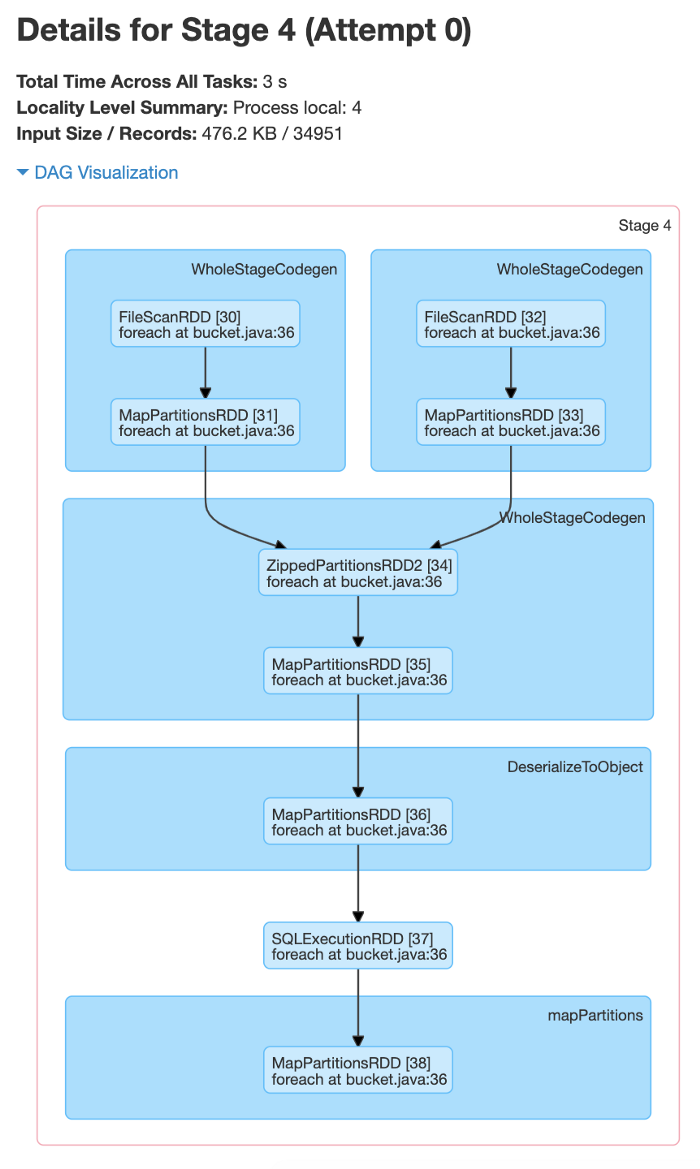
When not using bucketing, the analysis will run ‘shuffle exchange’ as seen in the above screenshot. We have 3 stages for all jobs as there is shuffle exchange happening.
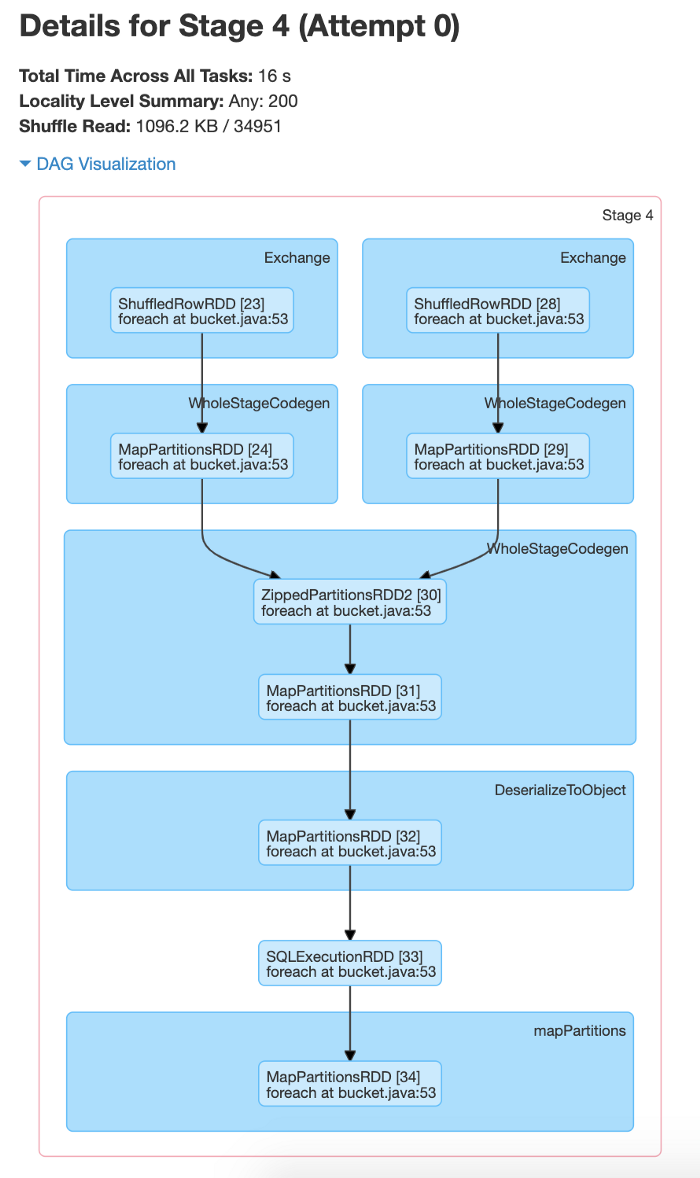
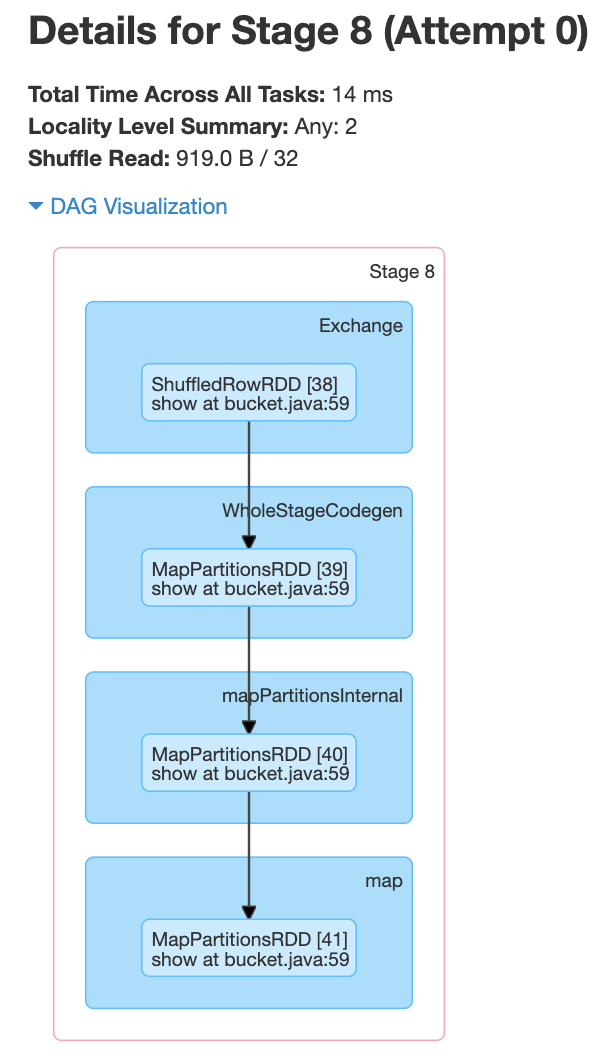
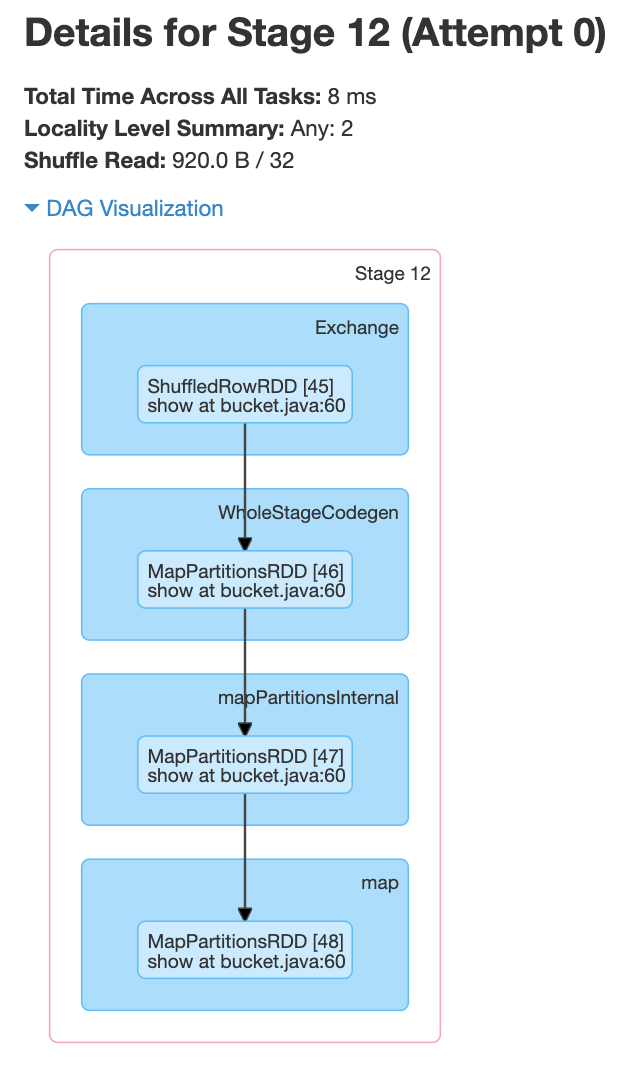
With Bucketing:- We are creating the two datasets from bucketed tables and then performing a join, groupBy, and distinct transformations.
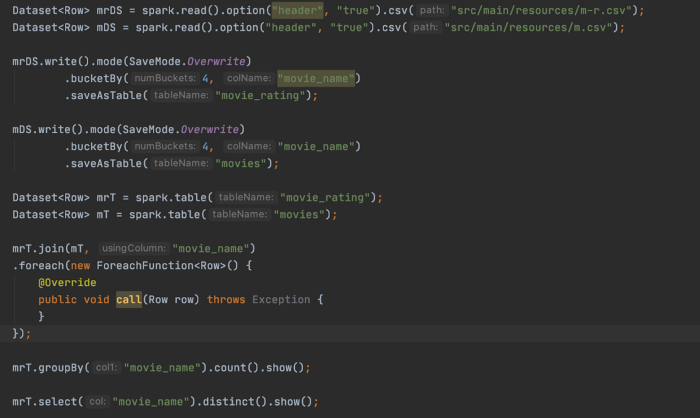

To do the bucketing, we are creating tables with a bucket (number of bucket and bucket column name), and then performing join and other transformations.
From the above screenshot, we can see that each of the jobs has one stage. In this case, a shuffle happened when creating the bucketed table .i.e., only once. And we can also see from the below screenshots that there is no shuffle happening within the stages.
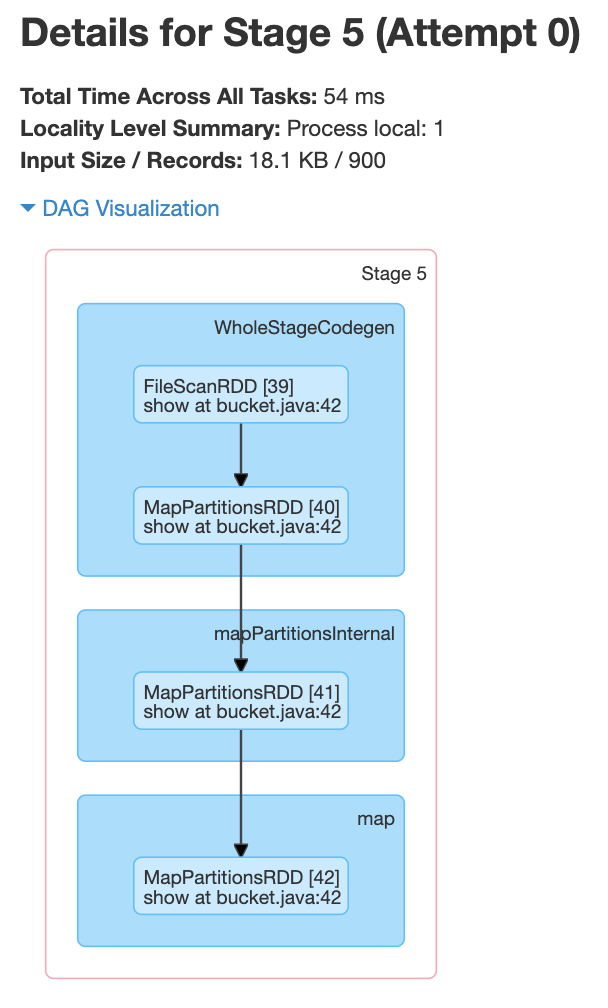
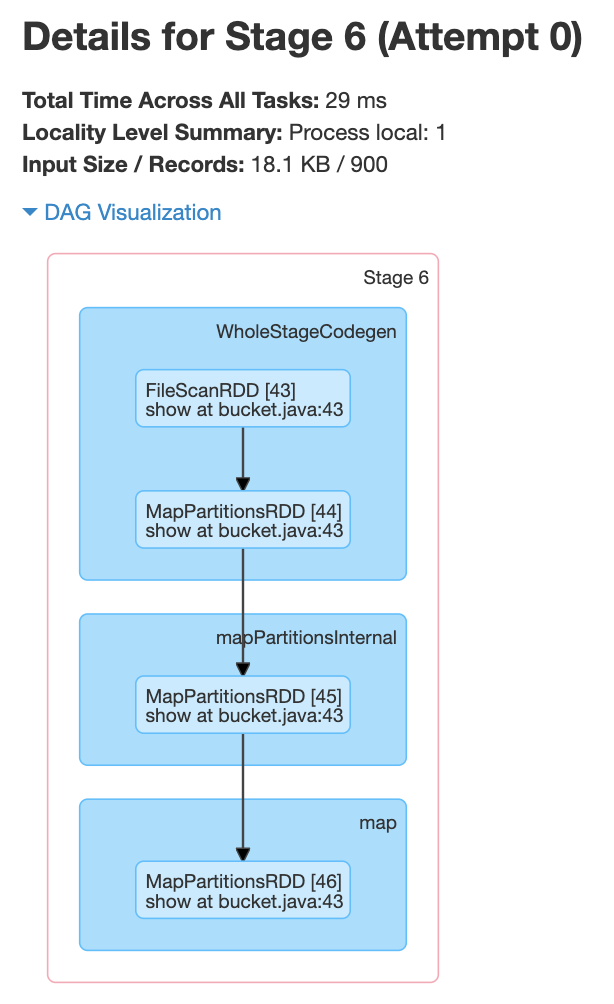
Advantages of Bucketing the Tables in Spark
-
Optimized tables/Datasets.
-
Optimized Joins when you use pre-shuffled bucketed tables/Datasets.
-
Enables more efficient queries when you have predicates defined on a bucketed column.
-
Optimized access to the table data. You will minimize the table scan for the given query when using the WHERE condition on the bucketing column.
-
Similarly, you can distribute the data across various buckets hence optimal access to table data.
-
Transformations that require data shuffle will be benefited.
Spark SQL bucketing limitations:
-
The bucketing technique in Spark SQL is different from Hive which gives way to an expensive migration process from Hive to Spark SQL.
-
Spark SQL bucketing requires sorting on reading time which greatly degrades the performance.
-
When Spark writes data to a bucketing table, it can generate tens of millions of small files that are not supported by HDFS.
-
Bucket joins are triggered only when the two tables have the same number of buckets.
-
It needs the bucket key set to be similar to the join key set or grouping key set.
To remove the above limitations, there has been a series of optimizations added in Apache Spark from the last year so that the new bucketing technique can cover more scenarios. So the new bucketing makes Hive to Spark SQL migration more simple and efficient.
List of Transformations
The below transformations will be benefited by bucketing:
-
Joins
-
Distinct
-
groupBy
-
reduceBy
Conclusion
We should use bucketing when we have multi-joins and/or transformations that involve data shuffling and have the same column in joins and/or in transformation as we have in a bucket.
Also, check out our blog about understanding resource allocation configurations for a Spark application here. To get the best data engineering solutions for your business, reach out to us at Clairvoyant.
We don’t require bucketing if we do not have the same column in joins/transformations and buckets.