Stuck with Spark OutOfMemory Error? Here is the solution…
Clairvoyant aims to explore the core concepts of Apache Spark and other big data technologies to provide the best-optimized solutions to its clients. Through this blog post, you will get to understand more about the most common OutOfMemoryException in Apache Spark applications.
The objective of this blog is to document the understanding and familiarity of Spark and use that knowledge to achieve better performance of Apache Spark. You will be taken through the details that would have taken place in the background and raised this exception. Also, you will get to know how to handle such exceptions in real-time scenarios.
Overview
Apache Spark applications are easy to write and understand when everything goes according to plan. But it becomes very difficult when the spark applications start to slow down or fail, and it becomes much more tedious to analyze and debug the failure. And, out of all the failures, there is one most common issue that many of the spark developers would have come across, i.e., OutOfMemoryException.
java.lang.OutOfMemoryError: Java heap space
Exception in thread “task-result-getter-0” java.lang.OutOfMemoryError: Java heap space
This exception is of no surprise as Spark’s Architecture is completely memory-centric.
How to deal with OutOfMemoryException?
The OutOfMemory Exception can occur at the Driver or Executor level. Let us first understand what are Drivers and Executors.
-1.png) Apache Spark: Driver and Executors
Apache Spark: Driver and Executors
Driver is a Java process where the main() method of our Java/Scala/Python program runs. It executes the code and creates a SparkSession/ SparkContext responsible for creating Data Frame, Dataset, RDD to execute SQL, perform Transformation & Action, etc.
Executors are launched at the start of a Spark Application with the help of Cluster Manager. These can be dynamically launched and removed by the Driver as and when required. It runs an individual task and returns the result to the Driver. It can also persist data in the worker nodes for re-usability.
Each of these requires memory to perform all operations and if it exceeds the allocated memory, an OutOfMemory error is raised.
OutOfMemory at the Driver Level
OutOfMemory error can occur here due to incorrect usage of Spark. The driver in the Spark architecture is only supposed to be an orchestrator and is therefore provided less memory than the executors. You should always be aware of what operations or tasks are loaded to your driver. Few unconscious operations that we might have performed could also cause error.
Collect()
Example:
val data = df.collect()
Collect() operation will collect results from all the Executors and send it to your Driver. The Driver will try to merge it into a single object but there is a possibility that the result becomes too big to fit into the driver’s memory.
%20in%20spark.png) Collect() in spark
Collect() in spark
We can solve this problem with two approaches: either use spark.driver.maxResultSize or repartition. Setting a proper limit using spark.driver.maxResultSize can protect the driver from OutOfMemory errors and repartitioning before saving the result to your output file can help too.
df.repartition(1).write.csv(“/output/file/path”)
Broadcast Join
There could be another scenario where you may be working with Spark SQL queries and there could be multiple tables being broadcasted. When performing a BroadcastJoin Operation,the table is first materialized at the driver side and then broadcasted to the executors. In this case, two possibilities arise to resolve this issue: eitherincrease the driver memory or reduce the value for spark.sql.autoBroadcastJoinThreshold.
OutOfMemory at the Executor Level
Total executor memory = total RAM per instance / number of executors per instance
There are a few common reasons also that would cause this failure:
-
Inefficient queries
-
High concurrency
-
Incorrect configuration
Let’s understand these in detail.
1. Inefficient Queries
Example: Selecting all the columns from a Parquet/ORC table.
Explanation: Each column needs some in-memory column batch state. The overhead will directly increase with the number of columns being selected.
The Catalyst optimizer in Spark tries as much as possible to optimize the queries, but it can’t help you with scenarios like this when the query itself is inefficiently written.
Solution: Try to reduce the load of executors by filtering as much data as possible, using partition pruning(partition columns) if possible, it will largely decrease the movement of data.But there could be another issue that can arise in big partitions. You can resolve it by setting the partition size: increase the value of spark.sql.shuffle.partitions.
2. High Concurrency
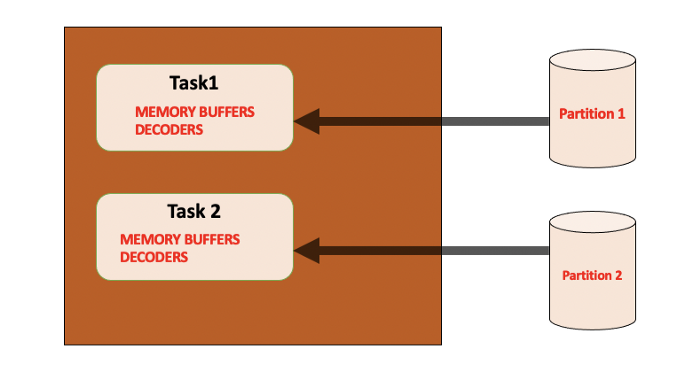 Apache Spark Parallel Processing.
Apache Spark Parallel Processing.
In case of an inappropriate number of spark cores for our executors, we will have to process too many partitions. All these will be running in parallel and will have their memory overhead; therefore, they need the executor memory and can probably cause OutOfMemory errors.
To fix this, we can configure spark.default.parallelism and spark.executor.cores and based on your requirement you can decide the numbers.
3. Incorrect Configuration
Each Spark Application will have a different requirement of memory.
There is a possibility that the application fails due to YARN memory overhead issue(if Spark is running on YARN). Therefore, based on each requirement, the configuration has to be done properly so that output does not spill on the disk. Configuring memory using spark.yarn.executor.memoryOverhead will help you resolve this.
e.g.
--conf “spark.executor.memory=12g”
--conf “spark.yarn.executor.memoryOverhead=2048”
or, --executor-memory=12g
Conclusion
By understanding the error in detail, the spark developers can get the idea of setting configurations properly required for their use case and application. Analyzing the error and its probable causes will help in optimizing the performance of operations or queries to be run in the application framework. To learn how to manage Kafka pragmatically, read our blog here.
We hope this blog post will help you make better decisions while configuring properties for your spark application. To get the best data engineering solutions for your business, contact us at Clairvoyant.
Thank you for reading this till the end. Hope you enjoyed it!
References
https://www.unraveldata.com/common-reasons-spark-applications-slow-fail-part-1/
https://blogs.perficient.com/2020/08/25/key-components-calculations-for-spark-memory-management/
https://medium.com/swlh/spark-oom-error-closeup-462c7a01709d