An introduction to S3 Select
Amazon S3 is unlimited, durable, elastic, and cost-effective in storing data or creating data lakes. Clairvoyant has years of experience creating data lakes with Amazon S3. Some applications frequently need to retrieve a subset of large datasets, in which case it is not feasible to process the entire object each time to get a subset of the object. Since this impacts the application's performance, Amazon S3 introduced a new feature called S3 Select. This blog is an introduction to S3 Select. Read more to understand how S3 Select is more efficient than in-memory object processing with a detailed example.
What is S3 Select?
S3 Select is an Amazon S3 feature that uses simple SQL expressions to retrieve a subset of S3 object content instead of retrieving the entire object. You can use SQL clauses, such as SELECT and WHERE to fetch data from objects stored in CSV, JSON, or Apache Parquet formats. It also supports objects that are compressed with GZIP or BZIP2 (only for CSV and JSON objects) and server-side encrypted objects.
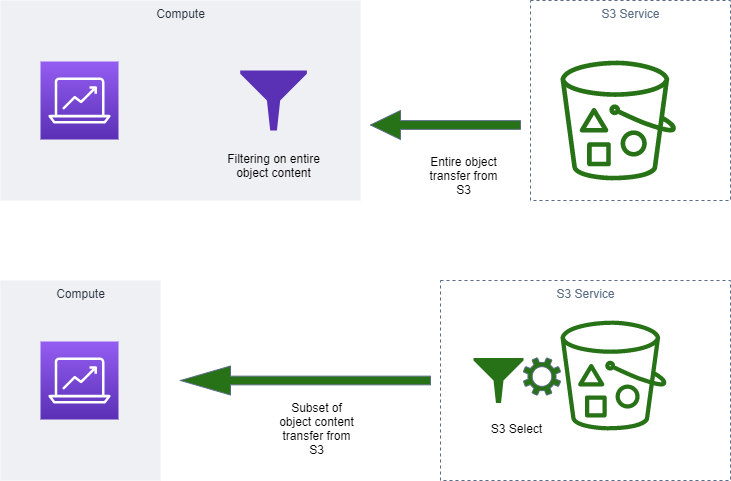 Data querying with S3 Select
Data querying with S3 Select
Features of S3 Select
-
Simple to use: Available as an API, no extra infrastructure or administration is required to use this feature. Simple standard SQL statements can be used in queries. Use SelectObjectContent API to pass queries to the S3 bucket and object key. It is easily integrated with other AWS services, such as AWS Lambda, EMR, etc.
-
Faster performance: By reducing the volume of data that has to be loaded and processed by your applications, S3 Select can improve the performance of most applications that frequently access data from S3 by up to 400%.
-
Cost-effective: The less you retrieve, the less you pay with effective queries.
Limitation of S3 Select
-
It supports a maximum of 256 KB length of an SQL expression.
-
It supports a maximum of 1 MB length of a record in the input or result.
-
Currently, only three object formats, namely CSV, JSON, or Apache Parquet are supported by S3 Select queries.
-
Few SQL clauses that are supported are SELECT, FROM, WHERE, LIMIT, etc.
-
It is not useful for complex analytical queries and joins.
-
The select query can execute on a single file at a time.
Cost of S3 Select
While calculating the cost of S3 Select, we have to consider three factors as mentioned below. The cost for region US-EAST(Ohio) with Standard Storage would be:
-
Amazon S3 Select — $0.0004 per 1000 SELECT requests
-
Amazon S3 Select data returned cost — $0.0007 per GB
-
Amazon S3 Select data scanned cost — $0.002 per GB
For example, if you have 50 GB of data in S3, you can perform nearly 100,000 SELECT requests a month, and return 20 GB of data out of S3 in a month. The approximate cost in this scenario has been discussed in the section below (as of Dec 2020).
Tiered price for: 50 GB 50 GB per month x 0.0230000000 USD = 1.15 USD Total tier cost = 1.1500 USD (S3 Standard storage cost) 100,000 SELECT requests in a month x 0.0000004 USD per request = 0.04 USD (S3 Standard SELECT requests cost) 20 GB per month x 0.0007 USD = 0.014 USD (S3 Select returned cost) 50 GB per month x 0.002 USD = 0.10 USD (S3 Select scanned cost) 1.15 USD + 0.04 USD + 0.014 USD + 0.10 USD = 1.30 USD (Total S3 Standard Storage, data requests, S3 Select cost) S3 Standard cost (monthly): 1.30 USD
The cost will vary from region to region, but we need to consider the data return and scanned factors while running queries.
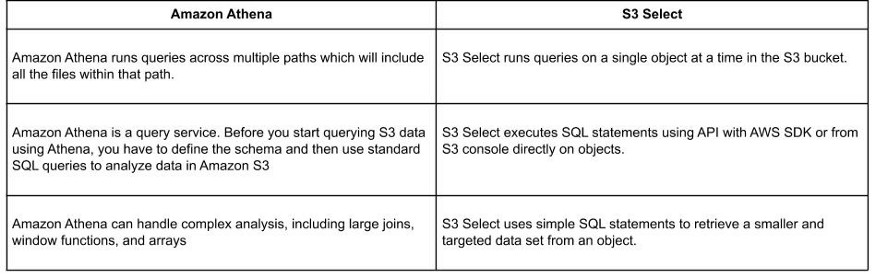
S3 Select vs Amazon Athena
Amazon Athena is another way to query S3 data, but if we compare Athena with S3 Select, then the following are the differences:
Example — S3 Select query with AWS SDK for Java
The below sample program demonstrates the performance of the S3 Select queries compared with the in-memory processing of the entire S3 object.
In this example, I want to retrieve sales data for a given region and country from 1 million sales records stored in the CSV format. To retrieve this data, I have used both ways- without S3 Select and with S3 Select, so we can compare both performance numbers.
After executing the above program, we found that without the S3 Select, to fetch 5359 sales records for the given criteria, the query required approximately 10 seconds. See the below program output:
Retrieving records from S3 without S3 Select Records Count 5359 Without S3 Select PT10.3490428S Retrieving records from S3 with S3 Select Records Count 5359 With S3 Select PT0.7449779S
Conclusion
Using S3 Select, we can accelerate S3 data querying performance with the help of simple SQL queries. We can also integrate S3 Select with other AWS services to improve the performance and reduce the cost. To learn about the best security practices of AWS S3, read this blog.
To get the best cloud IT solutions, contact us at Clairvoyant.
References:
https://aws.amazon.com/s3/pricing https://calculator.aws/#/estimate