Discover why it is necessary to modernize your data lakes and warehouses
In today’s business world, almost all companies are partially or entirely data-driven. The ultimate goal of data is to be efficiently leveraged to provide significant value that benefits a company. Every company that runs on data, collects and stores data in different volumes, varying formats, or from complex sources that most teams or ‘platforms’ may find challenging to handle.
Rise of Data Lakes
A lack of precise, timely, relevant, and trustworthy data access is one of the most common challenges organizations face. The ever-increasing volumes and the variety of data have pushed organizations into creating custom Data Lakes using Hadoop and related technologies. Data has started flowing into these data lakes and a multitude of transformations and aggregations started happening in the data lakes. The more curated business objects, usually called canonical data models, are being built and shipped to the more traditional data warehouses for further consumption by downstream applications.
Problems with traditional data lakes
Although the data lakes, typically built on-prem, solve the immediate volume and variety problems, they fail in the below cases:
-
Ephemeral workloads: On-prem data platforms need to provision their hardware based on their most resource-intensive use-case, even if the use-case is short-lived.
-
Scalability: Organizations often scramble to add extra resources to solve urgent surges of business problems. Moreover, scaling up and down clusters isn’t as easy and requires a lot of manual effort.
-
Adopting new tech: It is cumbersome to adopt a new tech-stack to solve a specific use case. Organizations tend to go beyond their comfort area to fit use-cases in the existing tech-stack rather than choosing the “right” solution.
-
Operational effort: Achieving reliability, security, performance, and cost optimization take a lot of effort and are often overlooked. Moreover, it requires in-depth knowledge of applications and the overall ecosystem. Automation effort often comes at the expense of losing valuable development hours.
This can hinder the path to accurate and fast business decision-making. Interestingly, most businesses that face this challenge function on traditional data lakes and warehouses. Though data warehouses are an integral part of an organization’s data architecture, the traditional data warehouses fail to meet modern-day demands. Hence, Modern Data Platforms!
Adaption to MDP is a necessity:
Modern Data Platforms are an agile and future-proof way to meet today’s demands and implement effective ways to leverage data and meet business needs. When we talk about Modern Data Platforms, we tend to approach them from two different perspectives-
-
the technology involved in processing the data,
-
and the data’s varying sources, types, and management techniques.
It is necessary to marry these two perspectives to deliver an effective modern data platform that can quickly and easily deliver data insights to businesses and their customers.
What makes Modern Data Platforms ‘Modern’?
In contrast to the above-mentioned challenges presented by traditional data lakes and warehouses, Modern Data Platforms tend to be a lot more agile in accepting various workloads, low on CAPEX, and yield faster value of your data. These are ‘modern’ demands of today’s data-driven organizations which are fulfilled by Modern Data Platforms, making them equally ‘modern’ and futuristic.
Modern Data Platform facilitates:
-
Optimized use of hardware resources. Organizations pay for the usage rather than ownership. This solves scalability issues by giving customers control on the spend w.r.t the usage.
-
Cross-cutting concerns like security, monitoring, reliability, disaster recovery, etc. are foundational concerns and are solved at the early stages.
-
Fine-grained use of technology:
Segmented Data storage: Use of correct data stores for specific concerns. For e.g. trying to use rdbms to store low-latency key-value data, just because you have an rdbms may not be the best choice. Often transactional data will require different data stores than data used for analytical purposes. Data can also be segregated based on latency and usage frequency (hot, warm, or cold storage).
Segmented compute loads: Resource demands are different for different kinds of jobs. For e.g. ETL jobs, streaming jobs, adhoc queries, machine learning jobs, applications using microservices; all have different needs of computing power. MDP will facilitate separate resources for these usages, thereby achieving optimum performance.
-
Advanced analytical capabilities that allow compatibility with all Business Intelligence processes to deliver deeper insights, map out opportunities, and make accurate futuristic forecasts.
MDP Architecture; which routes to take? On-prem or Cloud?
The question is whether you can achieve all the above traits of a Modern Data Platform in an on-premise environment or not. Possibly yes, but doing so will require a lot of budget in capital expenditure, expertise and most importantly, time. That leaves us with no option other than adopting the cloud.
Building Modern Data Platforms on GCP
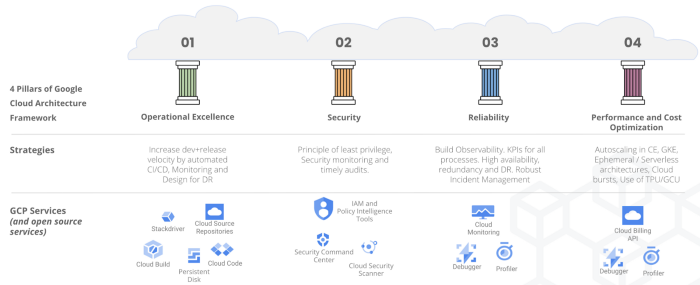
It’s fair to say that Google understands huge volumes of data better than most. The various products in the GCP suite provide unique features in building what we describe as a Modern Data Platform. Although other cloud providers like AWS and Azure have equivalent offerings, few products in GCP have set it apart from the competition. I’d like to call out 3 promising products:
-
BigQuery: GCP’s answer to the MPP data warehouse is an excellent choice in creating a core piece of MDP. Although AWS Redshift is a serious competition, Bigquery outperforms in areas like cost, and simplicity of use. A key highlight is that BigQuery is serverless, whereas Redshift is more dedicated in nature. Also, BigQuery charges very little for storage but adds extra for each query. Redshift on the other hand charges simply by the storage. That makes BigQuery a better choice if you have large amounts of data but have random patterns of data access. The reason to choose BigQuery gets even stronger if you are just unsure of how you’ll use your data. We see BigQuery equivalent to the combination of Redshift + Athena.
-
GKE and Anthos: GCP’s Anthos has reduced the consumer’s vendor lock-in anxiety and made the cloud adoption experience much easier and unrushed. Anthos enables us to run Kubernetes clusters anywhere, in both cloud and on-premises environments. It gives a consistent managed Kubernetes experience with simple installs as well as upgrades validated by Google. This enables businesses to adopt cloud IT solutions only for the correct reasons and at a pace that is comfortable.
-
GCP AI Platform: This is the area where GCP hits it out of the park. Their fully managed, end-to-end platform for data science and machine learning brings together the data prep, AutoML, and MLOps in one complete, cohesive platform. Products like data-labeling service, what-ifs and explanations, Auto-ML, and hardware support like GCU and TPU have made “Point n Click Data science” a reality.
To summarize, modernizing our existing data lakes and warehouse isn’t a choice anymore, but a necessity. And cloud adoption is the best choice for implementing our next-gen modern data platforms. Hybrid environments help us get the best value from both worlds, by keeping transactional and more predictable loads that run all day on static resources and moving all the “few hours in a day” kind of loads to ephemeral resources.
It’s important to note that adopting GCP (or any cloud) will be a major shift in your IT, and that’s where cloud partners come in. We, at Clairvoyant, have been helping customers accelerate their cloud journey from wherever they stand currently. Our expertise in multiple clouds and on-prem environments, and handling petabyte-scale volumes have helped us create a more systematic and phased approach for cloud adoption for our customers.
For information on how Clairvoyant can help your organization adopt GCP, please contact one of our experts.