CNN-LSTM Architecture And Image Captioning
Initially, it was considered impossible that a computer could describe an image. With advancement of Deep Learning Techniques, and large volumes of data available, we can now build models that can generate captions describing an image.
Deep learning is one of the most rapidly advancing and researched fields of study that is making its way into all of our daily lives. It is a subfield of machine learning concerned with algorithms and inspired by the structure and function of the brain. In this blog we will be using Deep Learning Techniques of Convolutional Neural Networks and a type of Recurrent Neural Network (Long Short Term Memory) together.
CONVOLUTIONAL NEURAL NETWORK:
Convolutional Neural Network (CNN) is a Deep Learning algorithm which takes in an input image and assigns importance (learnable weights and biases) to various aspects/objects in the image, which helps it differentiate one image from the other.
One of the most popular applications of this architecture is image classification.The neural network consists of several convolutional layers mixed with nonlinear and pooling layers. When the image is passed through one convolution layer, the output of the first layer becomes the input for the second layer. This process continues for all subsequent layers.
After a series of convolutional, nonlinear and pooling layers, it is necessary to attach a fully connected layer. This layer takes the output information from convolutional networks. Attaching a fully connected layer to the end of the network results in an N dimensional vector, where N is the number of classes from which the model selects the desired class. Also learn about music genre classification using CNN in our blog here.
LSTM(Long Short Term Memory):
Long Short-Term Memory (LSTM) networks are a type of Recurrent Neural Network (RNN) capable of learning order dependence in sequence prediction problems. This is most commonly used in complex problems like Machine Translation, Speech Recognition, and many more.
The reason behind developing LSTM was, when we go deeper into a neural network if the gradients are very small or zero, then little to no training can take place, leading to poor predictive performance and this problem was encountered when training traditional RNNs. LSTM networks are well-suited for classifying, processing, and making predictions based on time series data since there can be lags of unknown duration between important events in a time series.
LSTM is way more effective and better compared to the traditional RNN as it overcomes the short term memory limitations of the RNN. LSTM can carry out relevant information throughout the processing of inputs and discards non-relevant information with a forget gate.
CNN-LSTM ARCHITECTURE:
The CNN-LSTM architecture involves using CNN layers for feature extraction on input data combined with LSTMs to support sequence prediction. This model is specifically designed for sequence prediction problems with spatial inputs, like images or videos. They are widely used in Activity Recognition, Image Description, Video Description and many more.
The general architecture of the CNN-LSTM Model is as follows:
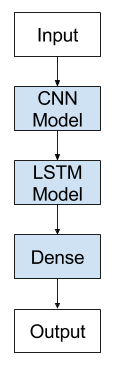
CNN-LSTMs are generally used when their inputs have spatial structure, such as the 2D structure or pixels in an image or the 1D structure of words in a sentence, paragraph, or document and also have a temporal structure in their input such as the order of images in a video or words in text, or require the generation of output with temporal structure such as words in a textual description.
IMAGE CAPTIONING:
The goal of image captioning is to convert a given input image into a natural language description.
In this blog we will be using the concept of CNN and LSTM and build a model of Image Caption Generator which involves the concept of computer vision and Natural Language Process to recognize the context of images and describe them in natural language like English.
The task of image captioning can be divided into two modules logically –
-
Image based model — Extracts the features of our image.
-
Language based model — which translates the features and objects extracted by our image based model to a natural sentence.
For our image based model– we use CNN, and for language based model — we use LSTM. The following image summarizes the approach of Image Captioning Generator.
For our image based Model -Usually rely on a Convolutional Neural Network model.
For language based models — rely on LSTM. The image below summarizes the approach.
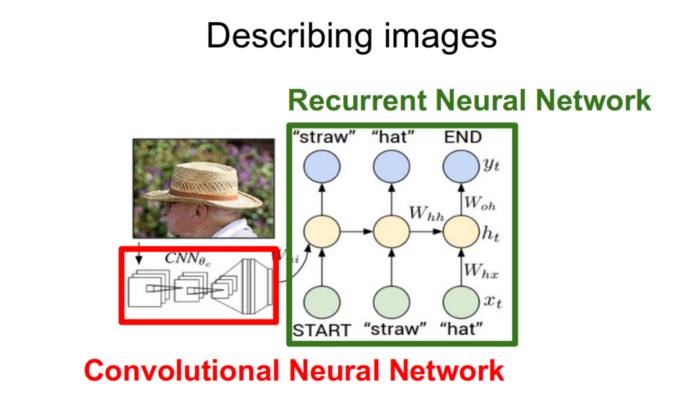
A pre-trained CNN extracts the features from our input image. The feature vector is linearly transformed to have the same dimension as the input dimension of LSTM network. This network is trained as a language model on our feature vector.
For training our LSTM model, we predefine our label and target text. For example, if the caption is “An old man is wearing a hat.”, our label and target would be as follows –
Label — [<start> ,An, old, man, is, wearing, a , hat . ]
Target — [ An old man is wearing a hat .,<End> ]
This is done so that our model understands the start and end of our labelled sequence.
DATASET:
In this blog we are using the Flickr8k_dataset. The dataset contains two directories:
-
Flickr8k_Dataset: Contains 8092 photographs in JPEG format.
-
Flickr8k_text: Contains a number of files containing different sources of descriptions for the photographs. Flickr_8k_text folder contains file Flickr8k.token which is the main file of our dataset that contains image name and their respective captions separated by newline(“\n”).
The image dataset is divided into 6000 images for training, 1000 images for validation and 1000 images for testing.
Here, we will break down the module into following sections for better understanding:
-
Preprocessing of Image
-
Creating the vocabulary for the image
-
Train the set
-
Evaluating the model
-
Testing on individual images
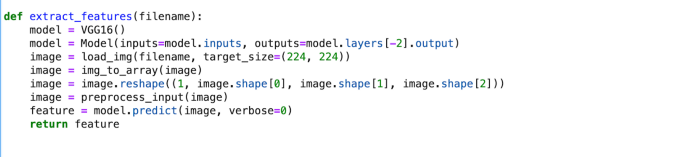
PREPROCESSING THE IMAGE:
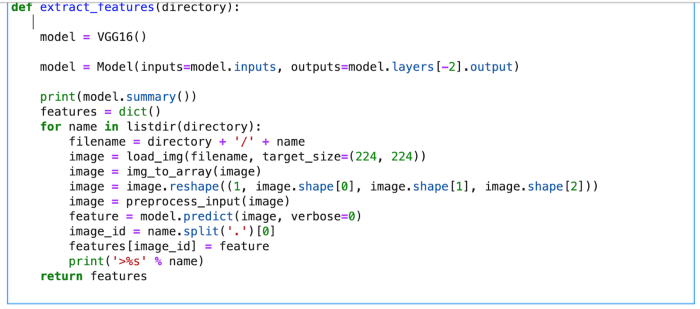
For image detection, we are using a pre-trained model called Visual Geometry Group (VGG16). VGG16 is already installed in the Keras library.
For feature extraction, the image features are in 224*224 size. The features of the image are extracted just before the last layer of classification as this is the model used to predict a classification for a photo. We are not interested in classifying images, hence we excluded the last layer.
CREATING VOCABULARY FOR THE IMAGE:
We cannot straight away take the raw text and fit it in a Machine Learning or Deep Learning model. We need to first clean the text, by splitting it into words and handle punctuation and case sensitivity issues. As computers do not understand English words, we have to represent them with numbers and map each word of the vocabulary with a unique index value, and we need to encode each word into a fixed sized vector and represent each word as a number. Only then the text can be readable by the machine and can generate the captions for the image.
We are going to clean the text in following order to achieve the size of vocabulary:
In order to achieve the above mentioned objectives, we define below 5 functions:
-
Loading the data
-
Creating a descriptions dictionary that maps images
-
Removing punctuations, converting all text to lowercase and removing words that contain numbers.
-
Separating all the unique words and creating vocabulary from all the descriptions.
-
Creating a descriptions.txt file to store all the captions.


To define the vocabulary, 8763 unique words are tokenized from the training dataset.

A snippet of the output file — description.txt file should look like this:

TRAINING THE MODEL:
In our dataset we have a file Flickr_8k.trainImages.txt file that contains a list of 6000 image names that will be used for training purposes.
We initially load the features extracted from the CNN model described above:

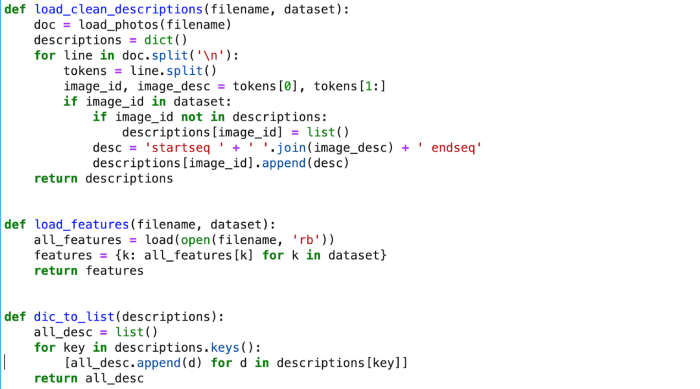
This will create a dictionary that contains captions for each photo from the list of photos.
TOKENIZING VOCABULARY:
Keras provides the Tokenizer class that can learn this mapping from the loaded description data.
This will fit a tokenizer given the loaded photo description text. We need to map each word of vocabulary with a unique index value.
Keras library provides a function that will be used to create tokens from vocabulary and then to a tokenizer.pkl pickle file.

DATA GENERATOR:
To make this a supervised learning task, we have to provide input and output to the model for training. We train our model on 6000 images and each image will contain a 4096 length feature vector and the corresponding caption for the image is also represented as numbers.This large volume of data generated for 6000 images is not possible to hold in memory, so we will be using a generator method that will yield batches.
The generator will yield the input and output sequence.

CNN-LSTM MODEL:
For image captioning, we are creating an LSTM based model that is used to predict the sequences of words, called the caption, from the feature vectors obtained from the VGG network.
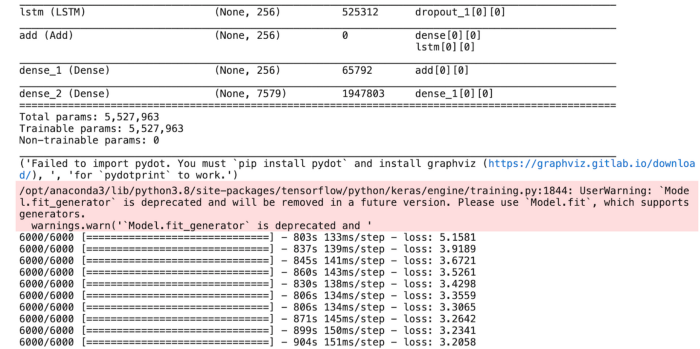
To train the model, we will be using the 6000 training images by generating the input and output sequences in batches from the above data generation module and fitting them to the model. We are training the model with 10 epochs.
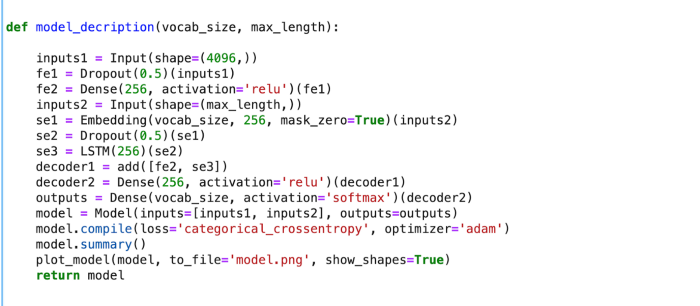

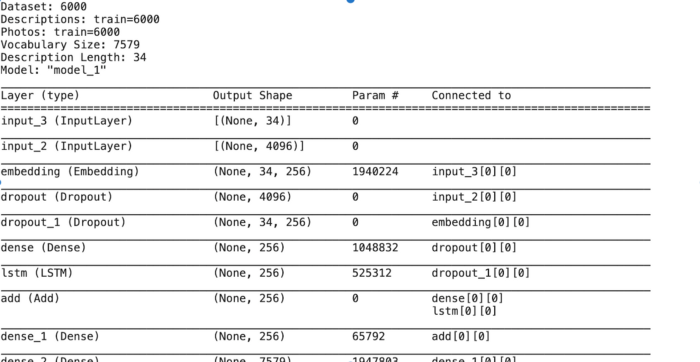
MODEL SUMMARY:
The model summary is seen as below:
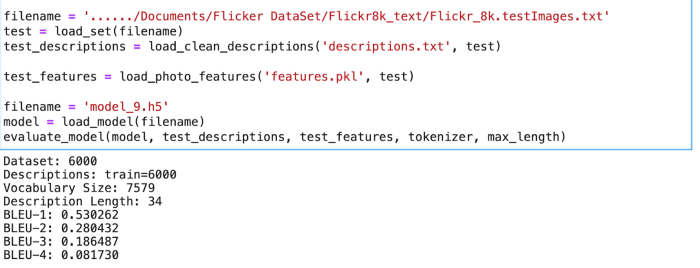
Model Evaluation — Bilingual Evaluation Understudy Score(BLEU’s):
BLEU is a metric for evaluating a generated sentence to a reference sentence. The score was developed for evaluating the predictions made by automatic machine translation systems. A perfect match results in a score of 1.0, whereas a perfect mismatch results in a score of 0.0.
The actual and predicted descriptions are collected and evaluated using the corpus BLEU score that summarizes how close the generated text is to the expected text.

TESTING THE MODEL:
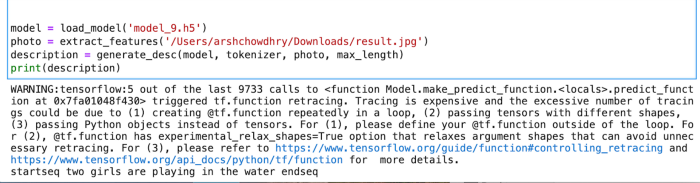
Now that the model has been trained, we can now test the model against random images. The predictions contain the max length of index values so we will use the same tokenizer.pkl to get the words from their index values.




CONCLUSION:
We have implemented a CNN-LSTM model for building an Image Caption Generator. A CNN-LSTM architecture has wide-ranging applications which include use cases in Computer Vision and Natural Language Processing domains.
Hope you enjoyed the post and was informative. To get the best artificial intelligence solutions for your business, reach out to us at Clairvoyant.
REFERENCES:
https://github.com/manthan89-py/Image-Caption-Generator/blob/main/Image%20Caption%20Generator.ipynb
https://medium.com/swlh/automatic-image-captioning-using-deep-learning-5e899c127387
https://medium.com/analytics-vidhya/cnn-lstm-architecture-and-image-captioning-2351fc18e8d7