What is fingerprint recognition?
Fingerprint recognition refers to the automated process of verifying a match between two fingerprints. Fingerprint recognition was one of the first techniques introduced for automatically identifying people, and today, still considered the best practice.
Due to their uniqueness and consistency over time, fingerprint recognition has been used for more than a decade now. But more recently, fingerprint recognition has become automated due to advancements in computing capabilities.
Fingerprint recognition is the process of comparing questioned and known fingerprints against another fingerprint to determine if the impressions are from the same finger or palm. It is the most popular fingerprint recognition biometric up to date. Fingerprint recognition can utilize a number of approaches to classification. We can use fingerprint recognition algorithm for authentication purposes because of the following rules:
-
A fingerprint will remain unchanged during an individual’s lifetime.
-
Fingerprints have general ridge patterns that permit them to be systematically classified.
-
A fingerprint is an individual characteristic because no two fingers have yet been found to possess identical ridge characteristics.
In this blog, we try to give comprehensive detail about feature extraction and talk about different intelligent biometric techniques in face and fingerprint recognition for enhancing images, such as Edge detection and adaptive thresholding. Feature extraction consists of Ridge detection and Minutiae extraction to generate a template, after which a query image is matched using the metric ROC AUC curve.
DATASET
Sokoto Coventry Fingerprint Dataset (SOCOFing) is a biometric fingerprint database designed for academic research purposes. SOCOFing comprises 6,000 fingerprint images from 600 African subjects and contains unique attributes such as labels for gender, hand and finger name, and synthetically altered versions with three different levels of alteration for obliteration, central rotation, and z-cut.
The dataset contains the following files:
-
It has two main directories — Real and Altered directory
-
The altered directory is divided into:
-
Altered-Easy
-
Altered-Hard
-
Altered-Medium
-
-
The Altered directory contains synthetically altered versions of fingerprint biometric images with three different levels of alteration for obliteration, central rotation, and z-cut
-
The Real directory contains Real human fingerprints (No alteration)
IMAGE PRE-PROCESSING:
Image enhancement and pre-processing techniques such as smoothing, thresholding, and edge detection make features more prominent in data for extraction to be more accurate. The following pre-processing techniques are used:
-
Image Smoothening and Blurring
-
Thresholding
-
Edge Detection
Image Smoothening and Blurring:
In blurring an image, we make the color transition from one side of an edge to another side in the image. This is done to average out rapid changes in pixel intensity. It is an example of applying a low-pass filter to an image. There are many types of blurring available, but for this blog, we used Median Blur and Gaussian Blur techniques.
Gaussian Blur:
In the Gaussian Blur operation, the image is convolved with a Gaussian filter instead of the box filter. The Gaussian filter is a low-pass filter that removes the high-frequency components. We can perform this operation on an image using the Gaussian blur() method. The syntax for Gaussian Blur is:
GaussianBlur(src, dst, ksize, sigmaX)
The result of Gaussian blur on the thumb gives us a result something like this:
Gaussian Blurred Image

For further information, please visit this link.
Median Blur:
The Median blur operation is similar to the other averaging methods. Here, the central element of the image is replaced by the median of all the pixels in the kernel area. This operation processes the edges while removing the noise.
We can perform this operation on an image using the median blur() method. The syntax for this operation is:
medianBlur(src, dst, ksize)
Median Blurred Image

For further information, please refer to this link.
Thresholding:
Thresholding comes under the class of image segmentation, in which we change the pixels of an image to make the image easier to analyze. In thresholding, we convert an image from color or grayscale into a binary image. Most frequently, we use thresholding as a way to select areas of interest in an image while ignoring the parts we are not concerned with.
Otsu’s Image Thresholding:
In Otsu Thresholding, a value of the threshold isn’t chosen but is determined automatically. Usually, this technique produces the appropriate results for bimodal images.
Otsu’s thresholding method involves iterating through all the possible threshold values and calculating a measure of spread for the pixel levels on each side of the threshold. The aim is to find the threshold value where the sum of foreground and background spreads is at its minimum. These are the results of Otsu’s thresholding when implemented on three random fingerprints.
Otsu’s Thresholding Image1
-4.jpeg)
Otsu’s Thresholding Image2
.png)
Otsu’s Thresholding Image3
-Nov-02-2021-07-11-58-87-AM.png)
Edge Detection:
Edge detection is an image-processing technique used to identify the boundaries (edges) of objects or regions within an image. Edges are considered the most important features associated with images. We come to know of the underlying structure of an image through its edges. Computer vision processing pipelines, therefore, extensively use edge detection in applications. In this article, we will be using three methods for edge detection. They are as under:
-
Prewitt Edge Detection
-
Sobel Edge Detection
-
Robert Edge Detection
-
Prewitt Edge Detection:
This method is commonly used to detect the horizontal and vertical edges in images. The following are the Prewitt edge detection filters:
Prewitt filters for vertical edges detection
-4.png)
Prewitt filters for horizontal edges detection
-3.png)
-
Sobel Edge Detection:
It is used in image processing and computer vision techniques, particularly within edge detection algorithms where it creates an image emphasizing edges.
The Sobel–Feldman operator is based on convolving the image with a small, separable, and integer valued filter in the horizontal and vertical directions and is therefore relatively inexpensive in terms of computations.
This uses a filter that gives more emphasis to the center of the filter. It is one of the most used edge detectors and helps reduce noise and provides differentiating, giving edge response simultaneously. The following are the filters used in this method-
Sobel filters for vertical edges detection
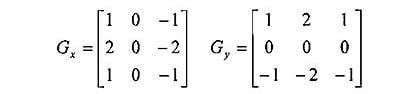
-
Robert Edge Detection:
The idea behind the Roberts cross operator is to approximate the gradient of an image through discrete differentiation, which is achieved by computing the sum of the squares of the differences between diagonally adjacent pixels. It uses the following 2 x 2 kernels or masks:
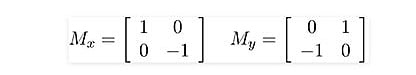
Following are the results of edge detection done on random three fingerprints:
Roberts
-2.png)
Sobel
-2.png)
Prewitt
FINGERPRINT MATCHING TECHNIQUES:
There are a large number of approaches for fingerprint matching. But broadly, they are classified into three families:
-
Correlation Based Matching
-
Minutiae-based matching
-
Pattern-Based Matching
Minutiae Based Matching is the most popular and widely used technique, being the basis of the fingerprint comparison made by fingerprint examiners. Minutiae are extracted from the two fingerprints and stored as sets of points in the two-dimensional plane. Minutiae-based matching essentially consists of finding the alignment between the template and the input minutiae sets that results in the maximum number of minutiae pairings.
The next step after the enhancement of the image is the extraction of minutiae. The enhanced image is binarised first in this step. The skeleton of the image is then formed. The minutiae points are then extracted by the following method. The binary image is thinned as a result of which a ridge is only one pixel wide. The minutiae points are thus those which have a pixel value of one (ridge ending) as their neighbor or more than two ones (ridge bifurcations) in their neighborhood. This ends the process of extraction of minutiae points. The results from minutiae extraction are as follows:
Minutiae extraction results
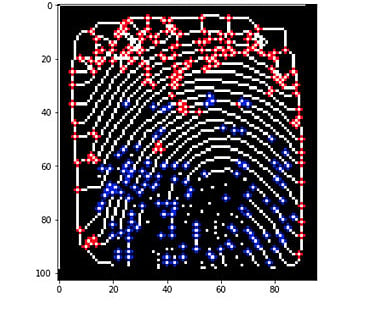
Now, we are going to create a convolutional neural network (CNN) model that can predict the gender of a fingerprint.
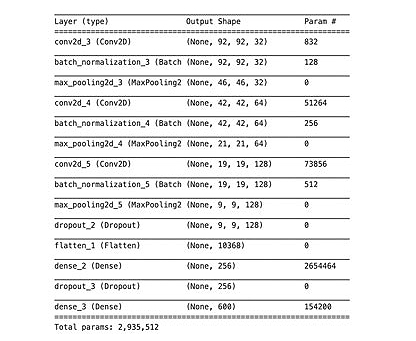
BUILDING THE MODEL:
We are going to create two datasets, SubjectID datasets, and fingerNum datasets. These datasets will be used to train two different models in the next steps.
-
We will use the TensorFlow library to build our model
-
We will build a CNN model from scratch, having three convolutional layers
-
We will introduce methods to prevent overfitting, including L2 Regularization, BatchNormalization, Dropout regularization, Early Stopping, and ReduceLROnPlateau
-
After, we will add a flatten layer, a hidden dense layer, and then an output layer
-
our input_shape = [96,96,1] (1 is as a result of our images in gray-scale)
-
Max pooling layers (MaxPooling2D) have a pool size of 2
-
We have only one hidden layer (Dense) with 256 units; the activation function is ‘‘relu’’

We are going to train the models for 30 epochs. This is where we set our validation_split value, validation_split = 0.2 tells the model to set apart 20% of the training data for validation.
Now we can see the accuracy of the model:
-3.png)
-2.png)
The above plot visualizes the training process with accuracy Id and Finger Recognition. We see that the curve for both training accuracy and validation accuracy comes closer, and finally, we get an accuracy of around 98%.
Testing the Model:
After training our model, we want to test it on data it has never seen and how well it will perform. We will test our model on the real fingerprint images we have in our test variable.
Now we randomly pick a fingerprint from test data to predict both its Id and fingers name. When both the predictions are correct, then we can say this kernel works great with two models.
-1.png)
Conclusion
To conclude, we were able to build a simple CNN from scratch that predicts person id and finger number from fingerprint images. We extracted specific labels, converted images to arrays, pre-processed our dataset; we also set aside train data for our model to train on. Each model reaches around 98% accuracy, so eventually, the kernel can predict with great confidence!
The code can be seen through this link.
Clairvoyant creates simple and effective techniques and technology used in fingerprint recognition to train models and make them work from scratch in real-world applications. The true potential of any data is seen and used to continually unlock progress and advance human endeavors in all fields of business and the public sector.