Introduction to Convolution Neural Network (CNN) and OpenCV in Emotion Recognition
Clairvoyant is at the forefront of harnessing the power of data to reap actionable insights for our clients through AI-, ML-, and related data solutions. Borrowing from our vast experience working on Deep Learning and Machine Learning problems, we have created a Deep Learning Model which is capable of accurately recognizing human emotions through rigorous training using superior quality datasets.
In this blog, we will build a Convolution Neural Network (CNN) architecture and train the model on FER2013 dataset for Emotion recognition from images.
DATASET:
This model is capable of recognizing seven basic emotions as following:
-
Happy
-
Sad
-
Angry
-
Surprise
-
Disgust
-
Fear
-
Neutral
The FER-2013 dataset consists of 28,709 labeled images in the training set and 7,178 labeled images in the test set. Each image in this dataset is labeled as one of seven emotions: happy, sad, angry, afraid, surprise, disgust, and neutral. The faces have been automatically registered such that the face is more or less centered and occupies about the same amount of space in each image.
In this blog, we will be using Deep Learning and Computer Vision.
WHAT IS DEEP LEARNING:
Machine Learning (ML) and Deep Learning are subsets of Artificial Intelligence. Deep Learning represents the next evolution in Machine Learning. In Deep Learning, the model learns through an artificial neural network that is very much similar to a human brain and this allows the model to analyze data in a structure much similar to humans do. Deep Learning models don’t require a human programmer to intervene and tell what to do with the data. It is self-capable of learning from the extraordinary amount of data provided to it. For more information on Deep Learning, you can visit this link.
COMPUTER VISION:
Computer vision provides the ability for the computer to see as humans see. It is the part of computer science that is focused on replicating the intricate parts of the human visual system. It helps identify and process the objects in images through the computer.
Deep learning has delivered superhuman accuracy for image classification, object detection, image restoration, and image segmentation. It uses enormous neural networks to teach machines how to automate the tasks performed by human visual systems. It is a field that aims to gain a deep understanding through digital images or videos. For more information, visit here.
INTRODUCTION TO OpenCV:
There are some predefined packages and libraries in python as part of Computer Vision which can make our life quite simple and OpenCV is one of them. It helps us develop a system that can process images and real-time video using computer vision. OpenCV (Open Source Computer Vision Library) is an open-source computer vision and machine learning software library which is easy to import in Python. We will be using HaarCascade algorithm in the model. It is a machine learning-based approach where a cascade function is trained using a whole lot of positive and negative images. It is then used to detect objects in other images.
We’re using Google Colab as part of this blog. It’s a browser-based Jupyter notebook service that’s available for free. This service is fit for Deep Learning and Machine Learning applications. It does not require any additional setup or installation. It helps us to run Python code via the browser. It also allows us to share these notebooks without having to download them. You can learn more using this link.
Now that the concept is clear, let’s dive into some lines of code using Python and the aforementioned library, OpenCV:
1. Unzip the zipped file:

2. Import packages:

3. Initializing Training And Test Generators:
Keras ImageDataGenerator augments the images in real-time while the model is still training. Any random transformation can be applied to each training image as it is passed to the model. This not only makes the model robust but also saves the overhead memory.
When we run this cell, the total records in the output will be the addition of the training and testing data. In our model, we are using 28,709 images in the test and 7,178 images in the test set.
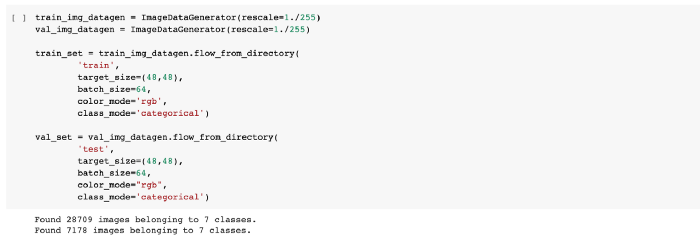
4. Building the Convolutional Neural Network (CNN) Model:
ResNet50 also known as Residual Networks is a classic neural network used in many computer vision tasks. The 50 in the ResNet stands for a convolution neural network that is 50-layer deep. The main aim of this model is to avoid poor accuracy as the model becomes deeper. ResNet50 is a pre-trained model on top of which we are going to train our own model.
ResNet model is proposed to solve the issue of diminishing gradient. The basic idea is to skip the connections and pass the residual to the next layer so that the model continues to train. Using this ResNet model on top of our CNN model, our models can go deeper and deeper.
For further information please visit this link.
The classic use of CNN is to perform image classification. There are different parameters that need to be considered for building this model.
-
Different Activation functions are used, such as Rectified Linear Unit (ReLU) and Softmax functions. Activation functions are used to get the resulting values in the range of 0 to 1 or -1 to 1 depending on the function. There are two types of activation functions, Linear and Non-Linear. For more information visit here.
-
Pooling layers are used to reduce the number of parameters when the images are too large. Downsampling reduces the dimensionality of each map but it retains the important features.
-
Max Pooling takes the largest element from the rectified feature map and downsamples it.
-
Dropout is a simple and powerful regularization technique for neural networks and deep learning models. A good value for dropout in a hidden layer is between 0.5 and 0.8. Input layers use a larger dropout rate, such as 0.8.
-
Dense is the only actual network layer in the model. It feeds all outputs from the previous layer to all its neurons, each neuron providing one output to the next layer. A Dense(1024) has 1024 neurons.
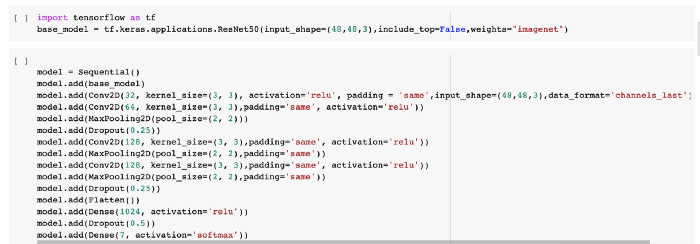
5. Compiling and Training the Model:
Categorical_crossentropy computes the crossentropy loss between labels and predictions. Crossentropy loss function is used when there are two or more label classes.
The Optimizer is one of the two arguments required for compiling a Keras model.
In this model, we are using Adam optimizer.
The epochs used in the model are 100.
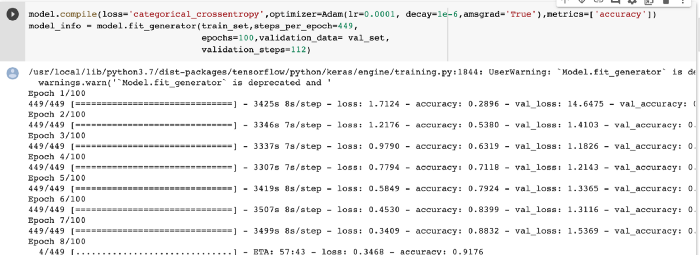
6. Saving the Model:

7. Graphical representation:
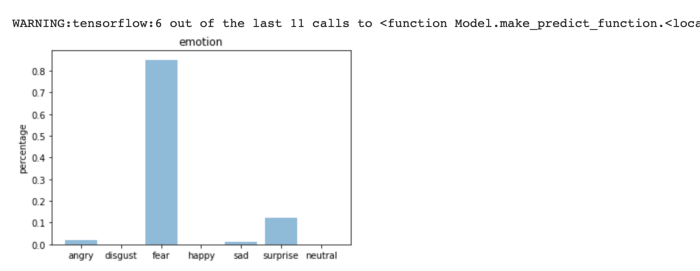
All the seven emotions that we are considering are given a graphical representation, with the y-axis as Percentage and the x-axis as the emotions (sad, happy, neutral, surprised, fear, anger, and disgust).

8. Result:



CONCLUSION:
Through this blog, I have tried to provide brief information on how Emotion Recognition works using Deep Learning. We trained our Convolutional Neural Network Model on top of pre-trained data (ResNet50)and we also used Computer Vision as part of this model. Haarcascade is the package used from OpenCV to detect objects in other images.
We trained the model with several images and then used the test images to see how the results match up. We trained the model through epochs. In this model, we have taken epochs as 100. Once the threshold is achieved by the model and if we further try to train our model, then it will provide unexpected results and its accuracy will also decrease. After that, increasing the epoch would also not help. Hence, epochs play a very important role in deciding the accuracy of the model, and its value can be decided through trial and error.
For this model, the accuracy that we achieved for the validation set is 63%. To further increase the accuracy of the model, we can either expand the training dataset we have or increase the step size for the model. Through these parameters, we can increase the model accuracy for this model. Learn about image caption generator in our blog here.
Hope you enjoyed the blog and found it informative! To get the best artificial intelligence solutions for your business, reach out to us at Clairvoyant.
LINKS:
https://realpython.com/face-detection-in-python-using-a-webcam/
https://github.com/komalck/FACIAL-EMOTION-RECOGNITION/blob/master/Facial_emotion_recognition.ipynb
https://towardsdatascience.com/building-a-convolutional-neural-network-cnn-in-keras-329fbbadc5f5