Design Patterns for containerized MicroServices
Design patterns help us build software faster without requiring the experience that led to the creation of those patterns. They help developers understand each other quickly, facilitating knowledge sharing and learning.
Clairvoyant’s software development methodology helps build easier, transparent, and faster solutions. We have also recently introduced accelerators which are code snippets with high reusability and the ability to easily customize to match the requirements of clients across domains. But taking the concept further, our software development philosophy is such that we divide our codes into containers, and design each of these containers to manage a certain functionality. Each container becomes a self-explanatory solution for certain problems.
For example, now that the idea of the “sidecar” container has spread in the developer community, we don’t need to explain the concept to those who have already worked on it before. We can instead, focus on how it can be used to solve a certain problem.
Another benefit of design patterns is that it helps us identify common components that can be implemented just once and then reused.
Distributed Design Patterns
To understand the motivation behind the design patterns, it’s helpful to know the benefits of using containers. Containers help us establish boundaries for applications, e.g if App A needs 8GB of memory, we can enforce that using a Docker. They also help us separate concerns with each container image having a well-defined function.
When our applications are packaged in containers and deployed to cloud environments, there are certain best practices we can follow to simplify the development process. Distributed design patterns help us implement these best practices when deploying our container-based application to a cloud environment. We can classify these design patterns into two types: single-node container patterns and multi-node container patterns.
Single Node Container Patterns
The basic element of design, when it comes to distributed systems, is the container. It is the basic building block for distributed system design patterns. The benefit of container use, as already mentioned, is that it provides an incentive for us to split an application into a group of containers, rather than having to run them all on a single container.
For example, let’s say we have an application that needs to monitor its configuration property files, to check whether they have been modified, and load those properties to memory if so. This provides an opportunity for separation of concerns. We could separate the application and the configuration loader module into two different containers that are co-scheduled. The application container would focus on the business logic, and the configuration container would be responsible for managing the configuration properties. With this approach, we can assign a higher priority to the application container, since it is responsible for handling end-user requests. In the case of high memory utilization, the configuration container could be terminated to keep the application container running.
In this way, we can achieve resource isolation by splitting our application into multiple containers that run on a single node. In addition, it increases the reusability of code. When another team builds a new application, they can simply reuse the configuration container instead of writing it all over again. Since the application is in a container that has an http interface, the other applications written in different programming languages can also use it. It also means that different modules independent of each other can be deployed resulting in more reliable deployments.
Sidecar Pattern
The sidecar pattern relies on the concept of an “atomic container group”. The atomic container group is a set of containers co-scheduled to the same machine, in addition to sharing some resources such as the network and some parts of the filesystem. In Kubernetes, this concept is represented by a Pod object.
In the sidecar pattern, we have two containers. The first container has the main application, for example, a web service. In addition to this container, there is another container referred to as the sidecar. This container is used to add functionality to the main service, without the main service knowing about it.
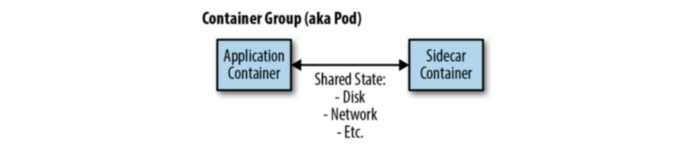
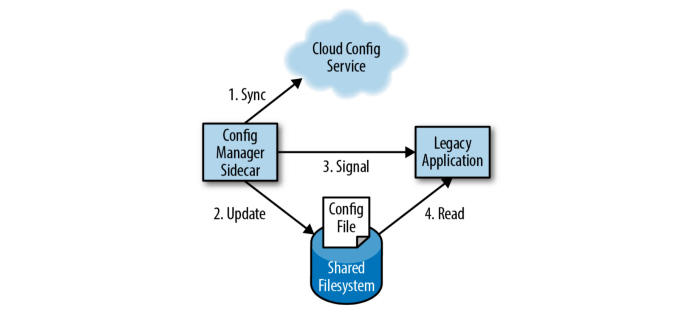
One use case for this pattern is configuration synchronization. A web service may store application properties using a configuration file located on the filesystem. In this case, updating a property would require a restart of the application. In a cloud environment, applications may need to be highly available and it would be preferable to update configuration settings without requiring a restart.
To solve this using the sidecar pattern, we would have two containers — the main container would be the server application and the sidecar container would be a configuration manager application. The two containers would be grouped together as part of a pod so that they would be co-scheduled. When the main application starts, it reads the configuration from the filesystem. The configuration manager application could read the latest value of the configuration, for example, from a properties file located on Git. If it identifies a difference between the local properties and the remote files, it would download the remote file and call an API on the main application to notify that it should reload the properties.
Ambassador Pattern
Similar to the sidecar pattern, the ambassador pattern relies on two containers that are co-scheduled. In the ambassador pattern, the interactions between the application container and external services are managed by an ambassador container.
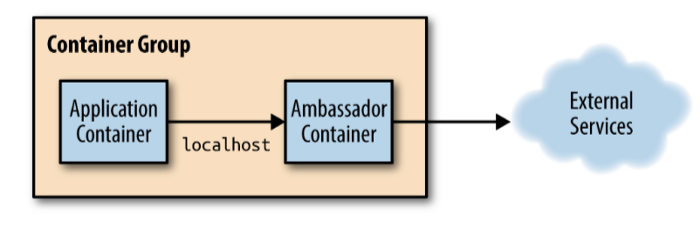
One of the benefits of this pattern is that, as with the sidecar pattern, reusability is increased. We can create an ambassador container and use it with different application containers.
An example use case for ambassador pattern is sharding a service.
In a sharded service, we create multiple replicas of the service. Each of these replicas is capable of serving a subset of the received requests. This is different from a replicated service (multiple instances behind a load balancer), where each replica is capable of handling any request. In a sharded service, we have a load-balancing node that receives requests and determines which replica, or shard, should process that request.
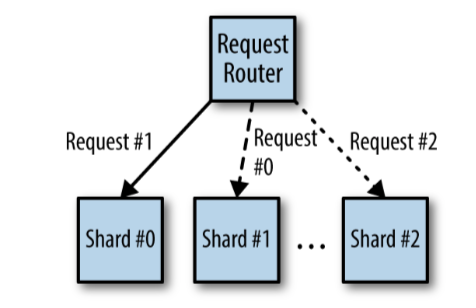
A sharded service is useful when you want to build a service that maintains state, such as a database. If you have a database where one instance is not able to store all the data, by sharding the database service and adding multiple instances with each storing a subset of the data, you are able to scale the service on the basis of the size of the data that needs to be stored. An ambassador container, with the logic required to route each request to the shard, can be introduced to process that request. The client application only connects to this application and is unaware of the shards.
Multi-Node Application Patterns
Until now you have learned the patterns you can apply to run them as reusable containers, and how these can be used by different deployed application containers.
Multi-Node deployment architecture helps in building scalable, resilient, highly available, and manageable systems.
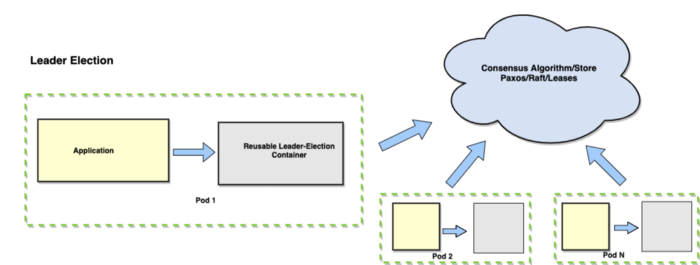
Leader Election Pattern
Replication is a common way of sharing the load among multiple identical instances of a component. One of the complex uses of replications is an application that needs to distinguish one replica as a “leader” from the set.
In a Distributed System, the most common problem is Leader election and there are a number of libraries/Algorithm (Raft, Paxos, Leases, software like Zookeeper, etc.) for performing the same. Implementation of these libraries is complex, difficult to understand, challenging, and redundant.
A system can run multiple leader selections in parallel, for example, to determine a leader in multiple shards (For example- a sharded cluster design in MongoDB, where each shard contains 3 member replica sets, in which one should be selected as a Primary and the others will work as secondaries).
We can apply a similar concept of reusability and link the Leader election library to the application to use the leader election container. Now multiple services can utilize the same container and application services are spared to focus on their business problems.
This pattern represents the principles of reusability, abstractions, and encapsulation.
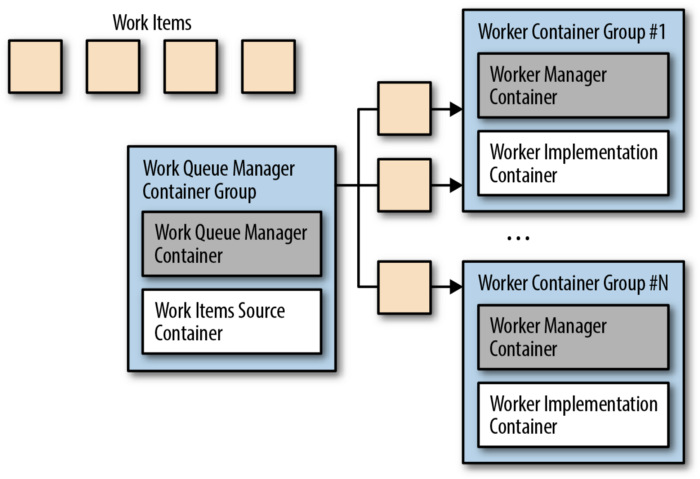
Work Queue Pattern
Work Queue System helps to perform a batch of work. In batch processing, each piece of work is completely independent of the other and can be processed independently too.
So, identify the functionality that can be provided by a shared set of libraries and any independent work from the actual work being done by your application and containerize them.
Work queue is another example of a distributed system. The goals of Work Queue system are to make sure that each piece of work is processed within a certain amount of time. To handle each task efficiently, workers can be scaled up and down.
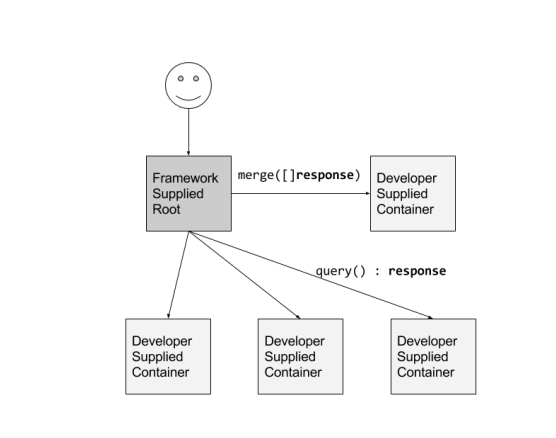
Scatter/gather (a.k.a. Fan Out/Fan In) Pattern
The last distribution pattern that we want to highlight is the Scatter/gather (a.k.a. Fan-out/Fan-In) pattern. This pattern helps you achieve parallelism in servicing requests, enabling you to service the client significantly faster than you would if you had to serve them sequentially.
In this system, the external client sends an initial request to the “root” or “parent” node. This root fans-out the request to multiple servers to perform parallel computations. Each shard returns partial data, and the root gathers the response from other shards and returns a single response.
This kind of pattern is commonly used in search engines. If you notice, building such systems requires a lot of boilerplate code: fanning out the requests, gathering the response, handling client requests, etc. These codes are quite generic and can be containerized and reused by the application containers.
Conclusion
Similar to the Object-Oriented programming that leads to “Design patterns” to solve commonly occurring problems, we can see that container based architectures also lead to design patterns for container-based distributed systems.
In this post, we have covered the single-container pattern for system management, single-node patterns for closely co-operating containers, and multi-node patterns for distributed algorithms. In all the cases, containers provide many of the same benefits as Object-Oriented systems do, such as reusability, abstraction, encapsulation, upgrading components independently, and the ability to be written in a mixture of languages.
The set of container patterns will grow as we evolve and revolutionize distributed systems programming as was the case with object-oriented programming in the earlier decades.
Are you looking for the best cloud computing solutions for your institution? Get in touch with one of our cloud experts.
References
- Design patterns for container-based distributed systems white paper by Brendan Burns and David Oppenheimer.
- Designing Distributed Systems by Brendan Burns