Amid the COVID-19 times and with stay-at-home orders in place, there has been a surge in technical articles and blog posts on AI/ML/DL that are interesting, challenging, and provide good learning opportunities. If you are also looking to work on a pet project or on a business use-case to build a custom object detection model, this can be your go-to article. I will keep this at a high level, outlining the approach and tools used, and also provide additional references at the end to delve deep.
YOLO (You Only Look Once) models have been popular for their performance and ease in object detection in images and videos. The authors Joseph Redmon and Ali Farhadi released the v3 model in 2018, and v4 paper is published in April. A comprehensive list of objects a trained YOLOv3 model on COCO dataset can detect are listed below-
person, bicycle, car, motorcycle, airplane, bus, train, truck, boat, traffic light, fire hydrant, stop_sign, parking meter, bench, bird, cat, dog, horse, sheep, cow, elephant, bear, zebra, giraffe, backpack, umbrella, handbag, tie, suitcase, frisbee, skis, snowboard, sports ball, kite, baseball bat, baseball glove, skateboard, surfboard, tennis racket, bottle, wine glass, cup, fork, knife, spoon, bowl, banana, apple, sandwich, orange, broccoli, carrot, hot dog, pizza, cake, chair, couch, potted plant, bed, dining table, toilet, tv, laptop, mouse, remote, keyboard, cell phone, microwave, oven, toaster, sink, refrigerator, book, clock, vase, scissors, teddy bear, hair dryer, toothbrush.
The YOLOv3 out of the box model already detects cars and here is a perception of cars from some sample images. You can download the model and sample images from here. To download additional images, instructions are provided in Download Images For Training section below.


As you can see, it detects all the cars in the above pictures of the parking lot. If we want to detect if a parking spot is open or occupied, we will have to build our own model, and we can approach this in two ways:
-
Train the model to detect all parking spots and then deduct the number of cars to identify open spots. This is a two-fold approach.
-
We can train the model to detect both open and occupied spots in one shot.
In both the scenarios, we need a lot of training data, and since we are looking at You Only Look Once (YOLO) concept, we will go with the second approach. Here are the steps we need to follow:
-
Download Parking lot Images
-
Annotate Images
-
Train the Model and Detect Objects
-
Download Images for Training:
Bing scraper can be used to download Google images for the categories below. We downloaded close to 1000 images. It was pretty straight forward but as you can expect, most of the data was noisy. We selected around 100 images that we wanted to use for training and testing. This is a considerably small volume to train a deep learning model, but in the next step, you will understand why it’s not a bad idea for a first pass.
parking lot, parking lot full, parking lot empty, cars parked, parking garage, parking garage inside, parking garage outside, street parking, parking lot at night, parking lot daytime, open parking, unmarked parking lot, urban parking, and rural parking
Image Annotation:
There are multiple open-source tools available to annotate images easily. Based on your preference and the nature of data you are working with, you can select from a web or desktop setup of categories. Here are a few-
All of them are pretty convenient to use and I decided to go with VOTT. Let’s take a look at an annotated image with both tags — Open and Occupied.
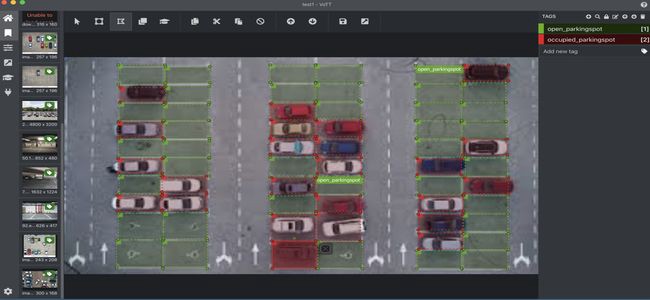
Imagine repeating this step on hundreds of images with lots of parking spots. Annotation of images taken from a bird’s eye view such as the one above is easier compared to annotating images taken from an eye level. This annotation of 100 images took a fairly significant amount of time and that’s all we aimed for, for a first attempt (thanks to my colleague Jason Yates for his help with annotation). As time permits, I plan to expand on this dataset in the upcoming days with help from my team. Therefore, it is important to choose an annotation tool and set it up so that the others can contribute too.
Once the images are annotated, export them in CSV format.
Train the Model and Detect Objects:
The pre-requisites for the training include converting VOTT_Csv_format to YOLO format, downloading darknet’s config and model weights, and converting them to a Tensorflow model.
Now we are ready to train the model with our annotated images and detect the objects in unseen images. For a complete hands-on experience with your own custom object detection, follow this article.
Let’s take a look at a few images after running them through the trained model.
 Parking Lot with One Car
Parking Lot with One Car
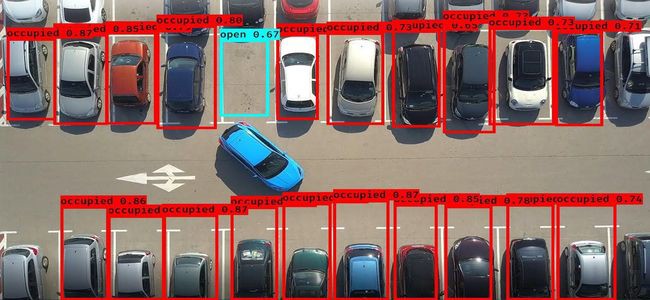 Parking Lot with Multiple Cars
Parking Lot with Multiple Cars
 Parallel Parked Cars
Parallel Parked Cars
As we can see, the classification of parking spots was pretty good given it was trained with a limited dataset. I noticed that the model’s performance was weak when the dividing lines weren’t clear or complete. By including similar images in the training data, we can improve the model’s performance. To get the best artificial intelligence solutions for your business, reach out to us at Clairvoyant.
References:
https://pjreddie.com/darknet/yolo/
https://blog.insightdatascience.com/how-to-train-your-own-yolov3-detector-from-scratch-224d10e55de2