At Clairvoyant, we possess vast experience in Big Data and Cloud technologies. We explore new concepts and tools in Big Data and cloud technologies to provide a better and accelerated digital experience to our clients.
In this blog, we are going to explore a technique to incrementally load data from Google Cloud SQL to Google BigQuery.
What are Google Cloud SQL and Google BigQuery?
Google Cloud SQL is a cloud-based, fully-managed relational database system provided by Google. These relational databases are generally used for transactional processing systems. It is maintained, managed, and administered by Google Cloud. Currently, it supports MySQL, PostgreSQL, and SQL Server database instances.
Google BigQuery is a cloud-based enterprise data warehouse solution. It is fully managed, serverless, and supports analytics over petabyte-scale data at blazing-fast speeds.
What are Incremental Loads?
Any new transactions or changes in the earlier transactions in an RDBMS transactional processing system are called incremental records. To perform incremental data load, synchronize new/changed data from RDBMS (here Cloud SQL) to your analytical processing system(here BigQuery).
Use Case of Incremental Loads:
Here is a use case that involves performing incremental loads of data from a Google Cloud SQL MySQL instance table to Google BigQuery table:
Problem Statement:
A company wants to maintain its employees' details in an RDBMS system’s MySQL table on a daily basis. And this data needs to be incrementally imported into the BigQuery table on a daily basis for analytical purposes.
Employee details are added to the MySQL table as a record of their present working status. If they are new or are presently working in the company, the working status is marked as ‘Working’ in the column working_status.
If an employee has left the company or is not working actively, the record would be updated with the change to the column working_status value to ‘Not Working’. Other changes to the employee column info are also updated in the table.
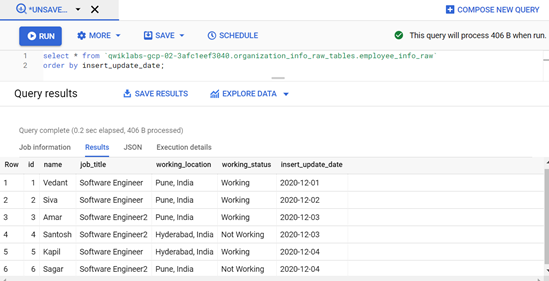
Any of the additions or updates in the records are identified with a date type column insert_update_date, so we can choose this column for incrementally loading data.
Source Cloud SQL MySQL instance and table Details →
-
Cloud SQL MySQL instance ID: testmysqlinstance
-
Source MySQL db (organization_info_tables) and table(employee_info) schema where employees’ info will be stored on a daily basis:
CREATE TABLE IF NOT EXISTS organization_info_tables. Employee_info ( id int, name varchar(255), job_title varchar(255), working_location varchar(255), working_status varchar(255), insert_update_date date, PRIMARY KEY (ID) );
-
Column working_status indicates whether an employee is presently working in the organization or not.
-
Column insert_update_date holds the date on which the employee info record was added or updated to this table.
Target BigQuery details →
-
Target table schema:
CREATE TABLE organization_info_raw_tables.employee_info_raw ( id INT64, name STRING, job_title STRING, working_location STRING, working_status STRING, insert_update_date DATE) PARTITION BY insert_update_date OPTIONS( description=”Bq Table to Store CloudSql Employee Table data” );
-
We are partitioning this target BigQuery table by insert_update_date for optimizing, i.e. saving the BigQuery resources if we want analysis filter data on dates.
Solution for implementing this incremental load problem:
Here we are going to see an approach of loading data from Cloud SQL MySQL as a federated source using EXTERNAL_QUERY() which can read tables directly from the Cloud SQL MySQL instance.
One column should be present in the source MySQL table which indicates the new addition of records or updates in the records. We can consider the column “insert_update_date” for performing incremental loads.
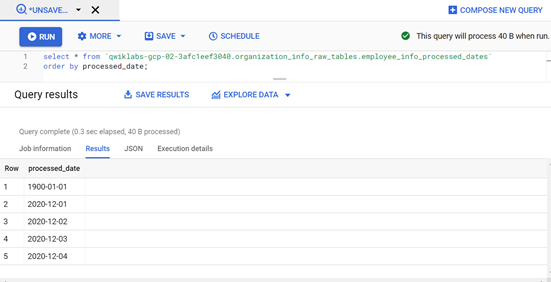
We will also be using one extra table (named employee_info_processed_dates) in BigQuery to maintain the dates whose data has already been loaded to BigQuery from Cloud SQL. We can use these processed dates to pick up the next incremental new unloaded dates from the source. The schema of the table is as follows:
CREATE TABLE organization_info_raw_tables.employee_info_processed_dates ( processed_date DATE) OPTIONS( description=”Bq Table to Store Processed dates of CloudSQL
employee_info Table” );
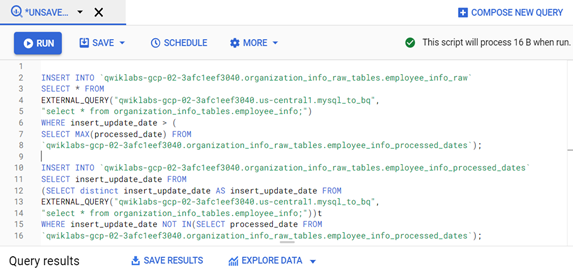
Actual Logical queries to perform incremental load are as follows:
Query-1: Logic to read the source MySQL incremental data and load to BigQuery table. It selects the records from a source that are not loaded/unprocessed based on the last value present in the column processed_date of table employee_info_processed_date.
INSERT INTO `.organization_info_raw_tables.employee_info_raw` SELECT * FROM EXTERNAL_QUERY(“”, “select * from organization_info_tables.employee_info;”) WHERE insert_update_date > ( SELECT MAX(processed_date) FROM `.organization_info_raw_tables.employee_info_processed_dates`);
Query-2: Query to insert and maintain processed dates whose data is loaded to BigQuery from MySQL in the previous insert step Query-1.
INSERT INTO `.organization_info_raw_tables.employee_info_processed_dates`
SELECT insert_update_date FROM (SELECT distinct insert_update_date AS insert_update_date FROM EXTERNAL_QUERY(“”, “select * from organization_info_tables.employee_info;”))t WHERE insert_update_date NOT IN(SELECT processed_date FROM `.organization_info_raw_tables.employee_info_processed_dates`);
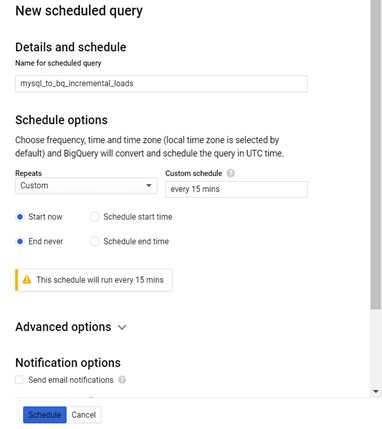
We can schedule both of these insert queries, such that they run in a sequential order one after the other, using the BigQuery Scheduler for continuous automated loads on a daily basis or with any custom frequency.
Practical implementation of this approach for incremental loads:
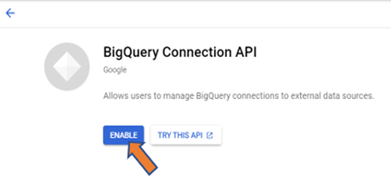
Step-1: Enable “BigQuery Connection API”, “BigQuery Data Transfer API” and grant bigquery.admin role:
Enabling “BigQuery Connection API” automatically creates a service account on your behalf and it has some roles, and permissions to connect to the Cloud SQL instances. Enabling “BigQuery Data Transfer API” allows the user to schedule the queries using BigQuery Scheduler. Check these APIs under the “API & Services” tab of GCP Console and enable them.
Example->
The user requires a bigquery.admin role to create and maintain Cloud SQL connection resources via BigQuery. Grant this role through Identity and Access Management or cloud shell gcloud commands.
Step-2: Connect BigQuery to Cloud SQL by creating a connection resource.
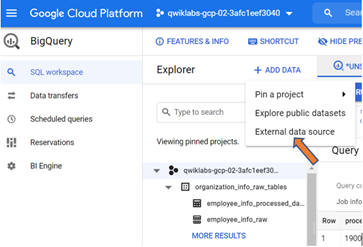
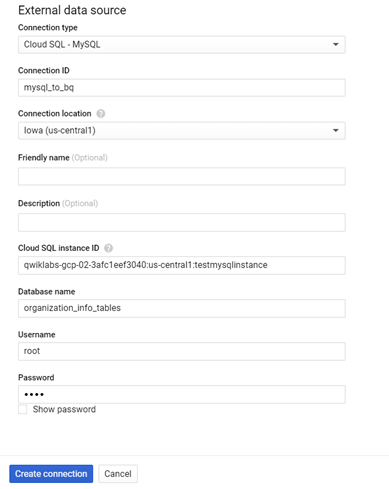
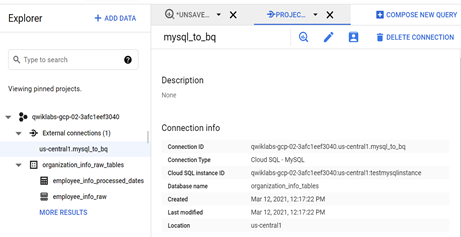
Note - Cloud SQL MySQL instance and BigQuery dataset must be in the same region. And also keep the connection resource in the same or nearby regions as the Cloud SQL region. Please check the Google documentation for more details.
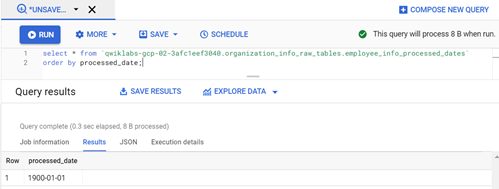
Step-3: Insert an initial (first time) lower limit date to the BigQuery table (employee_info_processed_dates) to start the first and subsequent dates incremental loads from source MySQL table to BigQuery table.
Query:
INSERT INTO `qwiklabs-gcp-02–3afc1eef3040.organization_info_raw_tables.employee_info_processed_dates` values (‘1900–01–01’);
Step-4: Schedule the incremental load logic of 2 insert queries running for continuous automated loads via BigQuery Scheduler.
Outputs results:
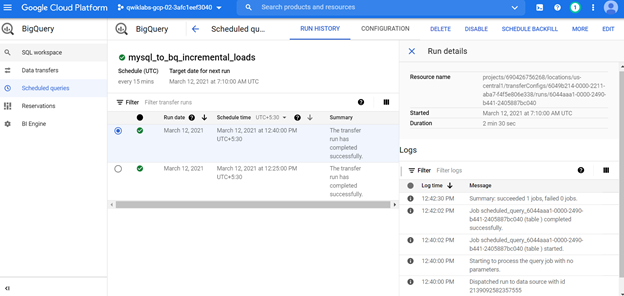
First Schedule of Incremental load:
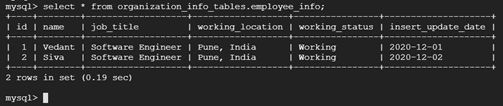
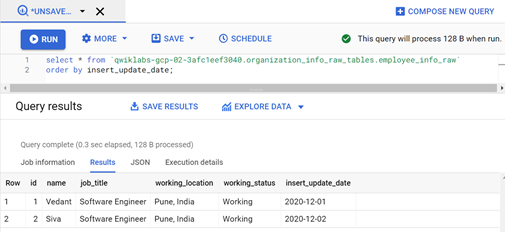
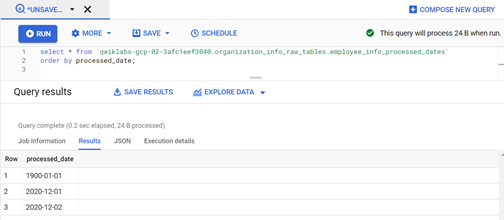
Second Schedule of incremental load with new records in the source MySQL table:
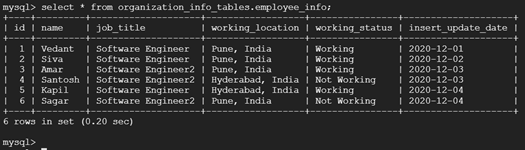
Conclusion:
We can leverage Cloud SQL federated queries to directly access Cloud SQL instances tables in BigQuery. We can implement a simple solution of incremental loading of Cloud SQL data to BigQuery using these federated queries and use BigQuery Scheduler to automate the process. This simple implementation does not require any effort in terms of coding, building the artifacts, and running the process manually.
References -
https://cloud.google.com/bigquery/docs/cloud-sql-federated-queries