At Clairvoyant, we possess vast experience in Big Data and Cloud technologies. We explore new concepts, tools in Big Data and cloud technologies to provide a better and accelerated digital experience to our clients.
In this blog, we will go through the basics of BigQuery, like its components, working and compare it with the on-premise data warehousing analytical tool Hive/Hadoop.
A Data Warehouse is a place that consolidates data from multiple source systems. Google BigQuery is a cloud-based enterprise data warehouse solution. It is fully managed and serverless which supports analytics over petabyte-scale data at blazing-fast speeds, and also allows you to execute complex SQL queries quickly. In addition, BigQuery integrates with a variety of Google Cloud Platform services and third-party tools which makes it more useful.
BigQuery basic components and their working
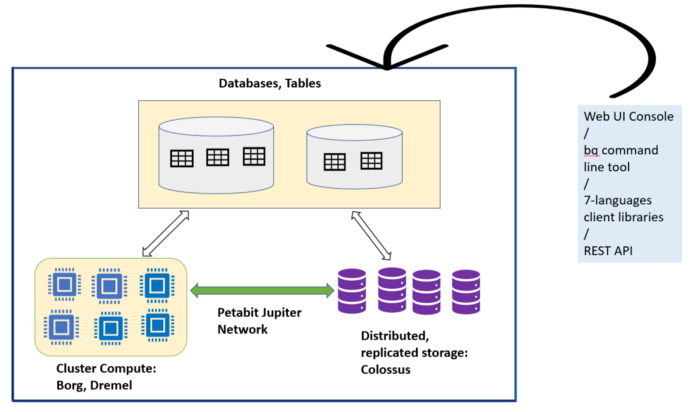 BigQuery components and its Behind the scenes working
BigQuery components and its Behind the scenes working
How does BigQuery Store Data?
BigQuery stores data in tables with its schema and organizes these tables into databases. In the background, BigQuery uses Colossus-Capacitor to store the table’s data. Colossus is Google’s distributed file system. Colossus manages cluster-level data distribution, replication, and recovery. Colossus file system splits the data into multiple partitions which enables blazing-fast parallel reads. To provide the highest availability of the data, BigQuery replicates the data across different geographical data centers.
Disk Inputs/Outputs is almost always been a key and expensive part of any Hadoop-Big Data analytics platform. Capacitor is a columnar storage format that stores BigQuery data at a low disk level. Capacitor compresses data and allows BigQuery to operate on the compressed data on the fly without decompressing it.
Advantages of having columnar storage:
-
Minimization of Traffic - Whenever you fire a query, required column values on each query alone are scanned and passed for query execution.
Example: a query ‘select address from project_test.test_db.employee’ would only access the address column values.
-
Better compression ratio - Since a similar type of data is organized together in columnar storage, it can achieve a higher compression ratio as compared to general row-based storage.
The combination of colossus and its underlying capacitor storage makes it possible to store and process terabytes of data per second. You can load your data into BigQuery native storage via batch imports or streaming flow imports.
Native vs External storage
Till now, we have gone through the native data storage for the BigQuery tables. BigQuery also performs queries against external/federated data sources without having to import data into the native BigQuery.
While accessing and reading an external data source, also known as federated data source, BigQuery loads data into Dremel engine on the fly. Usually, queries running against external data sources will be slower than native storage in BigQuery tables. The speed, and performance of these federated queries also depend on the external storage type. For instance, queries against Google Cloud Storage will perform better than Google Drive. In case the performance is a problem, then you should always first import your data into BigQuery table before running the queries. Querying to these kinds of external/federated data sources are useful when the source data is frequently updated like in Google drive sheets.
Currently, BigQuery can perform direct queries against the following sources:
-
Cloud Bigtable
-
Cloud Storage
-
Google Drive
-
Cloud SQL
Supported formats are:
-
Avro
-
CSV
-
JSON (newline delimited only)
-
ORC
-
Parquet
Compute/Processing:
BigQuery compute capability is built on top of Borg- a cluster management system and Dremel- a processing engine. A BigQuery client interacts with the Dremel engine via BigQuery web Console or bq command-line tool or client libraries or REST APIs.
Borg is Google’s scalable cluster compute resources management system that allocates the compute resources for the Dremel jobs. BigQuery takes advantage of Borg for data processing. Borg spawns multiple Dremel jobs which run concurrently across clusters of machines. Borg also handles fault tolerance along with cluster compute resource management.
Dremel and Borg can scale to thousands of machines by structuring computations as an execution tree. This multi-level execution tree architecture runs the process tasks on commodity machines. Dremel reads the data from Capacitors via Jupiter network, performs processing of the data and sends back the result to the client.
An important point in BigQuery architecture is that it separates the 2 concepts of compute (which is handled by borg and Dremel) and storage (colossus distributed file system). This separation of compute and storage enables both of them to scale independently which won’t affect the failure of either and this way it is more manageable, easy to maintain, and economical.
Network
Other than disk Input/Output operations, big data workloads require better network throughput because of their distributed processing fashion. And since compute and storage components are separated from each other in BigQuery, it requires a super-fast network that can perform the movement of terabytes of data in seconds from storage to compute jobs and across different processing machines for shuffling, and aggregating intermediate data.
Jupiter Network: It is the internal data center network that allows BigQuery to separate storage and compute. Compute and Storage communicate with each other via the petabit scale jupiter network. Shuffling of data that takes place between compute and storage uses Google’s super-fast network named Jupiter network to quickly transfer the data from one place to another with a speed of 1 Petabit/sec of total bisection bandwidth.
The meaning of Serverless and its benefits over Hive/Hadoop:
BigQuery is serverless, meaning the user does not need to install and manage clusters of machines, software, etc. on them, as these things are hidden, i.e. work behind the scenes. BigQuery allows us to concentrate on our analysis, data processing, creating visual dashboards instead of worrying about software, the infrastructure part, their scalability, availability, etc.
BigQuery eliminates the need for operational, and administrative efforts, thus saving time & cost for the employees, and companies who prefer to leverage it instead of the traditional data warehousing tool of Hadoop, i.e. Hive. Please check Quora discussions on this for reference.
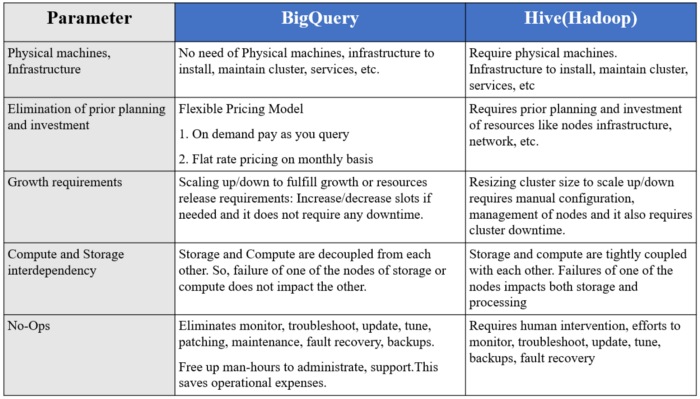 BigQuery Vs Hive/Hadoop Comparison
BigQuery Vs Hive/Hadoop Comparison
Conclusion:
By understanding the fundamentals of the Google Cloud Platform Data Warehousing Service developers, technical architects can decide their approach to choose between native and external storage as per their use case and design.
Comparing GCP BigQuery with the existing on-premise Hive/Hadoop helps technical architects, business stakeholders, and organizations to analyze why moving to the cloud computing services is important and beneficial over traditional on-premise Hive/Hadoop systems.
For more information or further queries, please email us at sales@clairvoyantsoft.com or call us at (623)282–2385. Learn more: https://www.clairvoyant.ai/